
According to the introductory post, AWS AppSync is a "serverless GraphQL service for real-time data queries, synchronization, communications and offline programming features.". I know that statement doesn't feature every 2018 buzz word, but it is getting pretty close. But what does it actually do?
Context
AWS has had a Firebase shaped thorn in its side since Google's acquisition of the company in 2014. The realtime store and sync functionality of Firebase's Realtime Database has been pretty alluring for developers, particularly for developing small UI-first MVPs. AWS has been slowly adding similar functionality in; client side DynamoDB access, IoT for Websockets. However the integration of these services has always been non-trivial. You are still doing a lot of glue work, which you don't need to do for Firebase. With the introduction of AWS AppSync, they have done all the hard-work for you, with the goal of having plug+play functionality similar to Firebase, with added flexibility and transparency.
Overview
Under the hood, AppSync leverages the aforementioned AWS services, but hides the implementation from you.
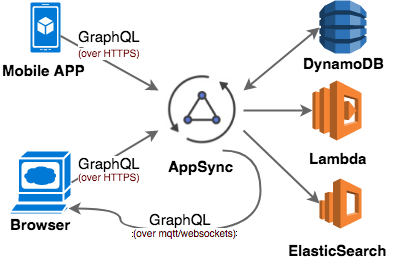
At a high level, AppSync exposes a GraphQL-based API, which then allows you to resolve your GraphQL fields to various backend services, which currently includes DynamoDB, Lambda and ElasticSearch. The other magic sauce is the real-time websockets integration (presumably using Amazon IoT under the hood), which pushes changes to fields back to your clients (if they have subscribed to changes).
For any non-trivial implementation, you will probably want to use Amazon Cognito to handle the authentication aspects of your application. Authorisation is enforced by AppSync, and can use either API key, AWS IAM, or a Cognito User pool for authentication.
Hacking Around
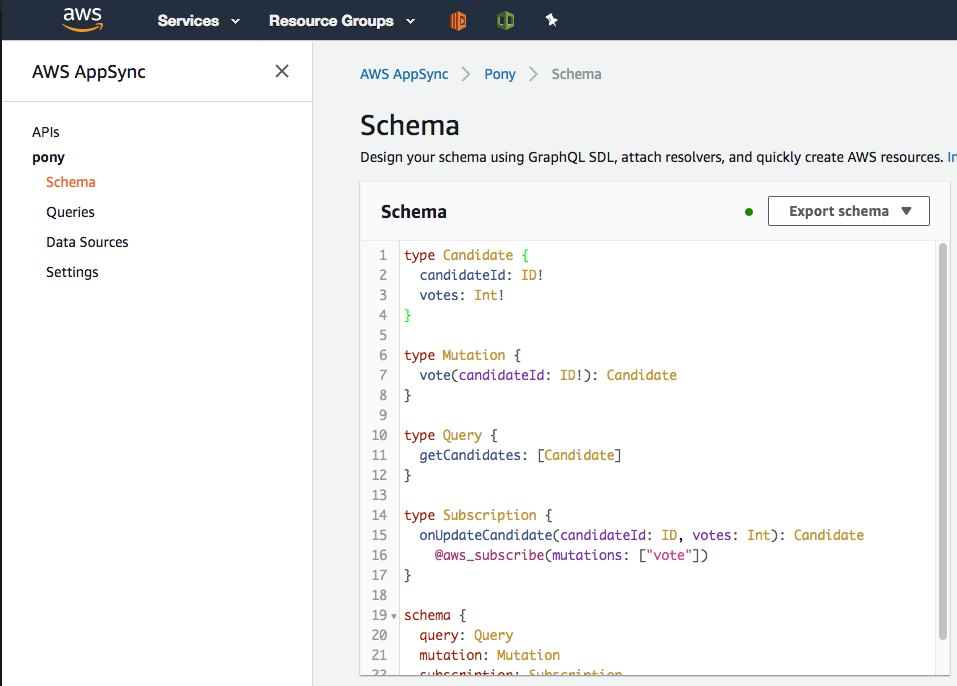
The GraphQL schema is the beating heart of AppSync. GraphQL is very powerful (particularly for developing complex cross-queries), but it takes a while to get your head around it. I have put together a super-simple schema example based on a rudimentary vote client to demonstrate the primary concepts. The sample schema allows you to vote for your favourite Pony emoji, and I have developed an app for it which we will discuss later on.
type Candidate {
candidateId: ID!
votes: Int!
}
type Mutation {
vote(candidateId: ID!): Candidate
}
type Query {
getCandidates: [Candidate]
}
type Subscription {
onUpdateCandidate(candidateId: ID, votes: Int): Candidate
@aws_subscribe(mutations: ["vote"])
}
schema {
query: Query
mutation: Mutation
subscription: Subscription
}
The most confusing part of the schema definition is the schema special type, which must have a query type attribute, and may have a mutation type. In addition, AppSync uses a subscription type to indicate which data will need to be pushed back to subscribed clients. The subscription mechanism, through the @aws_subscribe annotation, sends all valid mutation requests back to subscribed clients via Websockets. Once the schema has been successfully loaded (it has built-in validation), the next step is to "Create Resources". This allows you to automagically create DynamoDB tables based on the schema. It will also extend your GraphQL schema to add common mutations and queries to your schema.
Once a Data Source has been added, you can then attach custom Resolvers through the schema page. This entire setup reminds me of the old Lambda mapping behaviour, but I am sure it will improve over time. The resolver is a Velocity Template, which you use to generate a JSON request to the backend service, in this instance, DynamoDB. To demonstrate the complexity within the template, the following request-mapper is used to increment the vote counter for the vote mutation.
#set($allowedCandidated = ['carnival','racing','close','unicorn'] )
#set($isAllowedCandidate= $allowedCandidated.contains($ctx.args.candidateId))
$util.validate(${isAllowedCandidate}, "Candidated iD is not allowed")
{
"version" : "2017-02-28",
"operation" : "UpdateItem",
"key":{
"candidateId":{ "S": "${ctx.args.candidateId}" }
},
"update" : {
"expression" : "ADD votes :num",
"expressionValues" : {
":num" : { "N" : 1 }
}
}
}
This request-mapper does a rudimentary check to ensure that only allowed candidateIds are submitted. If it is an appropriate candidate, it will then increment the votes field. When you get into more complex queries, or when you need to do any kind of access-control enforcement, that needs to be coded into the template, which is going to get messy. You will want to ensure you have comprehensive API tests to ensure you don't accidentally remove your security controls. The request-mapper reminds me of the mapper functionality within the AWS API Gateway, which people generally ignore in favour of the Lambda proxy option.
Once you are happy with your resolver (as happy as you can be), the Queries tab on the left-hand side gives you the ability to "write, validate and test GraphQL queries". It's a great way of validating your understanding of GraphQL, and also to debug your resolvers.
# Query Example showing how to retrieve candidates
query preVote {
getCandidates {
candidateId,
votes
}
}
# Mutation example demonstrating how to call the mutation
mutation iLikeUnicorns {
vote (candidateId: "unicorn") {
votes
}
}
One of my favourite parts of the Queries page is that it actually uses the same GrapQL endpoint as your implementation. You can therefore use your browser is inspection tool to see the format of the GraphQL POST request if you are having trouble with your client side implementation.
Developing an Application: PonyVote
The batteries-included sample is great at demonstrating the various query, mutate, subscription behaviours, but it can be a bit overwhelming if you haven't used the Apollo GraphQL client before. I could see Amazon tailoring the sample generation to your schema definition in a future iteration of the project, but in the meantime you need to work out what goes where when you start playing with your own schema. However, they have also recently introduced something a little different.
AWS Amplify is a new, opinionated, JavaScript library for developing applications which leverage AWS services. The AWS customer-facing services are a hot-mess if you are not familiar with them, and Amplify tries to address that by making it super simple to use, both from a provisioning of services perspective, and a development integration perspective.
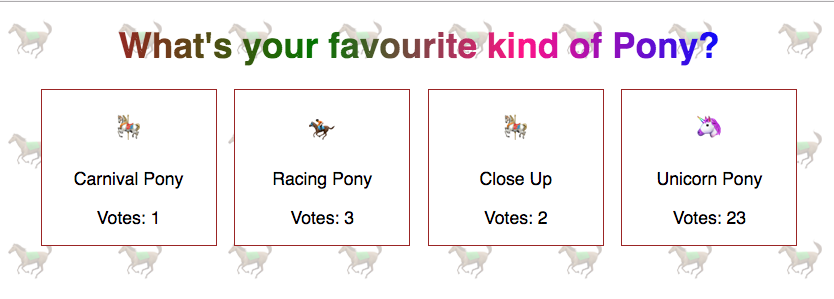
To give it a try, I developed a sample app, called PonyVote, which allows you to vote on your favourite pony emoji using GraphQL. The application is very basic, but provides a good overview of the query, mutate, subscribe concepts used by AppSync (by extension of GraphQL). Ignoring my poor React acumen, I did run into a couple of issues while writing the demo.
- You can't currently do optimistic responses with the React HoC implementation. This Github issue discusses the current thoughts around it. If you need to do that kind of thing, you can use the Apollo client, but it has a steeper learning curve.
- Amplifi uses the AWS Mobile CLI (another confusingly named product), to help with the automated configuration. For me I found it took a little bit too much control away from me, spinning up things left and right.
- The
awsmobile-clididn't seem to respect my environment profile settings whilst trying to configure it. Make sure you useawsmobile configure aws --profile SUPER_PROFILE_NAMEwhen you call it to explicitly point it at the correct profile.
Where would I use it?
GraphQL is itself great for situations where you have rapidly changing front-end requirements, and your application is query heavy. For those cases, I think AppSync is an incredibly powerful tool for quickly developing MVP type applications, and for low-volume applications (and hence, lower running costs). The advantage of using a standardised interface such as GraphQL is that if your application is getting too expensive to run on the platform, you can always move it without needing to re-write your frontend.
Where wouldn't I use it?
It doesn't make sense to use a service like this for high-volume applications. If you are looking at replacing something high-volume, such as a consumer banking site, you would be better off going bespoke. I believe that GraphQL should seriously be considered as an interface of choice, but AppSync itself is probably not a great starting point considering the pricing.
For query and modification operations, AppSync pricing is calculated based on per-request + data transfer, and subscriptions are charged per-request (in 5kb blocks) + subscriber connection minutes. Using some back-of-the-napkin maths, and excluding network transfer costs, let's say you have 400 000 users using your banking app each day, and each one makes 5 requests, that would be ~$248 a month worth of AppSync charges. Using a more traditional AWS environment, you could run a pair of m5.large instances for ~$143 a month, plus budget another $50 for an ALB, and you would be paying less than $200 for infrastructure. However you would then need to develop a server application using something like Apollo Server to handle your GraphQL requests.
AWS Amplify is still in really early stages. It is a great way of building something quickly, and allowing you to generate & hook into a bunch of different AWS services, but it also takes a lot of the control away from you. If you want more control over your development, or you need more control over the way it interacts with AppSync, you are probably better off using something like Apollo.
Conclusion
AWS AppSync is a great option for quickly developing applications on AWS, using a standards-based GraphQL API. You should seriously consider it for small, read focused applications, with constantly evolving entity models. AWS Amplify is a great introduction to the plethora of AWS front-end technologies, and will potentially be the go-to for developing AWS-first applications.
