
Over the past few years, event sourcing has become a popular pattern used in modern microservices architecture. The pattern's goal is to provide a reliable way of updating the database, while being able to publish messages on a queue/topic. A full explanation of the entire pattern can be found here.
In this blog post, I will explain how to design and deploy an event sourcing solution on Amazon Web Services (AWS). The principal AWS services used in our code will be Amazon DynamoDB, AWS Lambda and AWS Cloud Development Kit. The solution will simply track the requests made by a gateway to other services and persist them. This feature is very useful to have because it allows you to see the big picture, while also being able to identify which service is faulty.
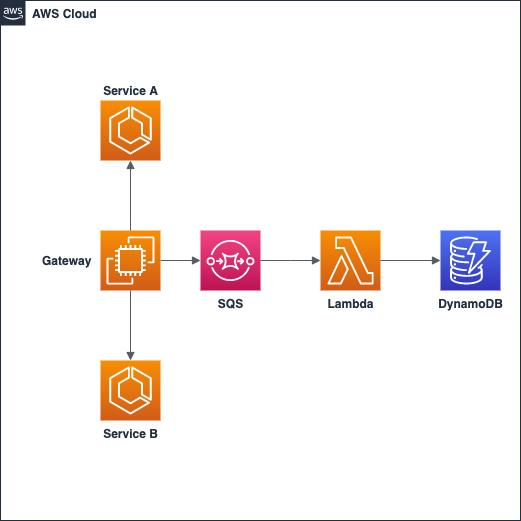
AWS Architecture
The AWS architecture will be composed of the following:
- Queue system
- Event producer
- Event consumer
- Datastore
The queue system is necessary in order to decouple, scale, and avoid blocking the event producers. In our case, only the gateway will produce events, but other producers can be plugged in later for other use cases.
The gateway will produce several events for which we will need a datastore that is highly performant and scalable. There are a lot of different NoSQL databases available (MongoDB, Cassandra, DynamoDB, etc). Since this blog post is focused on AWS, we will use the fully-managed solution: DynamoDB.
The final component is the service that will be in charge of persisting the events. AWS Lambda is the perfect service for that, and will allow you to benefit from all the features of the serverless world.
Overall, the architecture is pretty straightforward. Here is a diagram of the entire solution:
DynamoDB table modeling
For table modeling, I recommend using NoSQL Workbench for Amazon DynamoDB. It is useful in providing data visualization and query development features. I also recommend reading the best practices from the AWS developer guide, and this blog post detailing ten key rules of data modeling.
Here is how I designed my event table:
- ID
- UUID of the event
- RequestID
- UUID to group events of same request
- Timestamp
- The creation time of the event:
2020-05-01T20:00:00Z
- The creation time of the event:
- Type
- The type of the event:
MICROSERVICE_REQUEST
- The type of the event:
- Source
- The source of the event:
Gateway
- The source of the event:
- Data
- Additional data as a nested Map:
{"Name":"Microservice A"}
- Additional data as a nested Map:
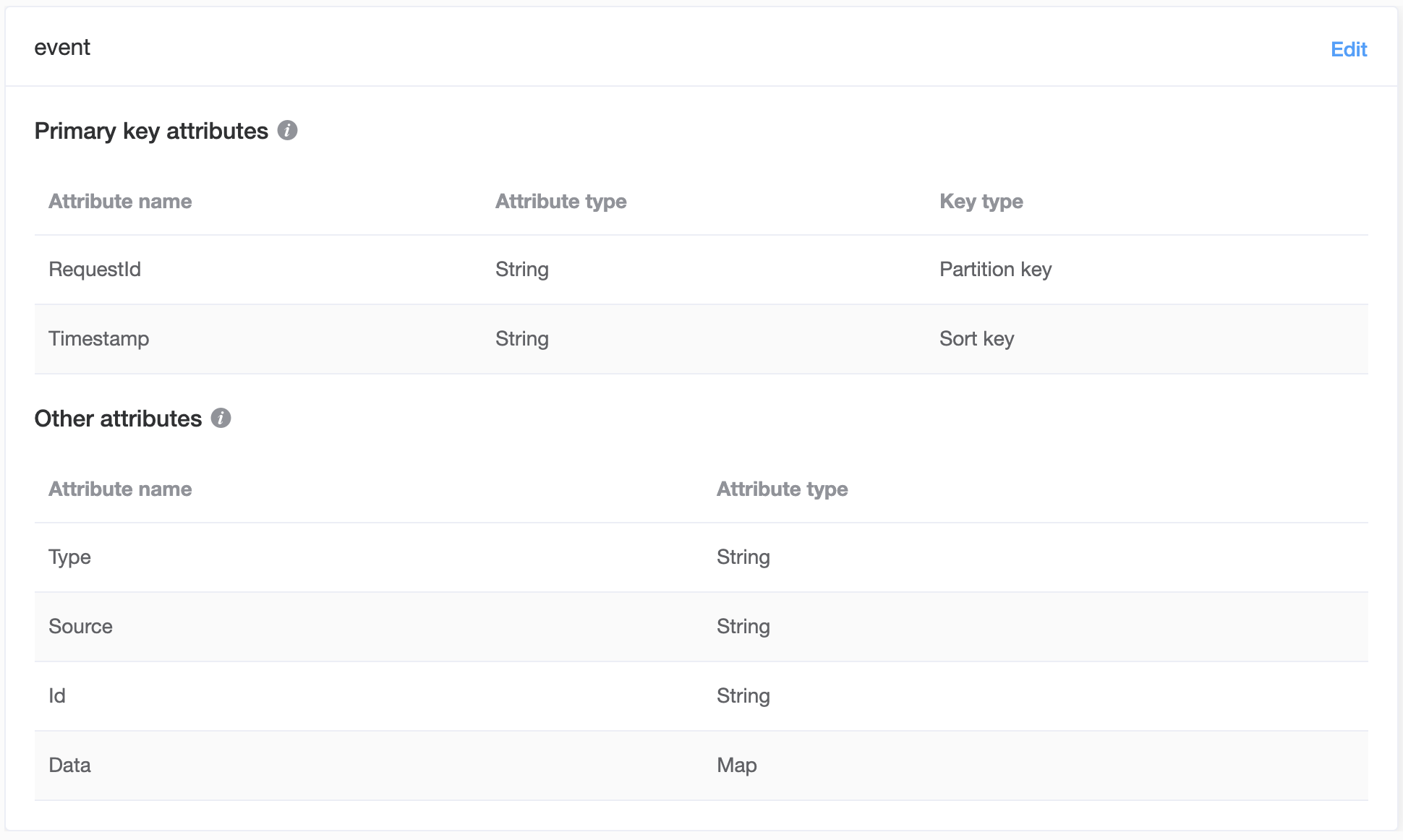
Two GSI (Global Secondary Indexes) are also created on Type and Source in order to handle access patterns, such as getting events from one type/source.
Here is how the aggregate view of the table looks with data:
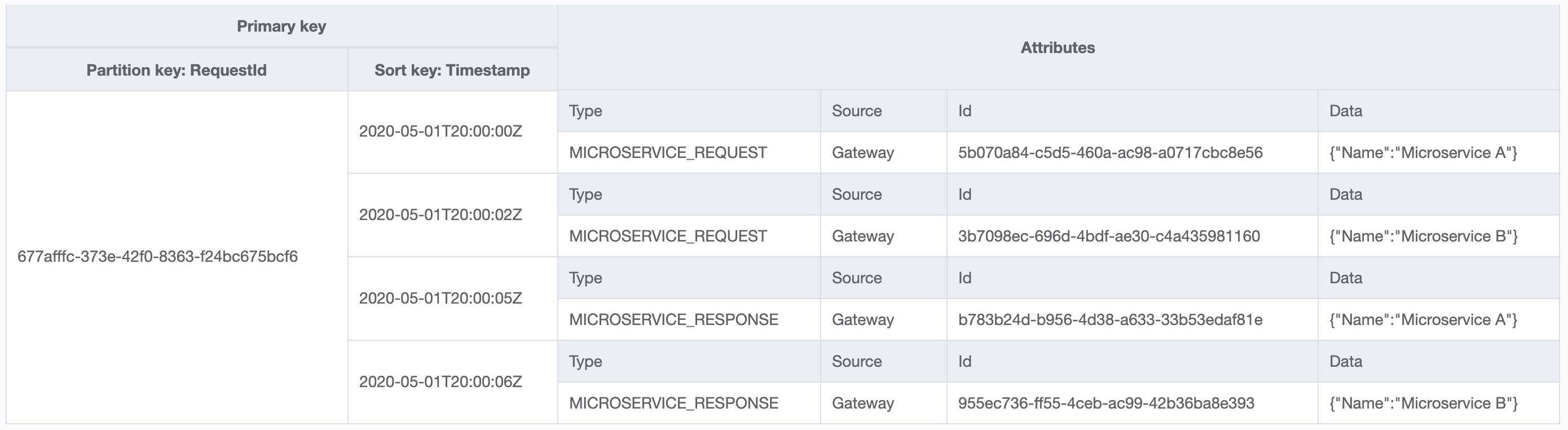
The events above describe requests made from the gateway to microservice A and B. They are all grouped by RequestId - that will allow us to inspect the whole flow.
Lambda
The Lambda's code is pretty simple since its role is to simply insert an item to DynamoDB.
var AWS = require('aws-sdk');
var dynamodb = new AWS.DynamoDB();
exports.handler = (event, context, callback) => {
Promise.all(event.Records.map((record) => {
var message = JSON.parse(record.body);
console.log('MESSAGE: %j', message);
// Build data object and ignore null values
var data = {};
for (let key in message.data) {
if (message.data[key]) {
data[key] = {
'S': message.data[key].toString()
};
}
}
// Build dynamodb item
var item = {
'TableName': 'event',
'Item': {
'RequestId': { S: message.requestId },
'Timestamp': { S: message.timestamp },
'Data': { M: data },
'Id': { S: message.id },
'Type': { S: message.type },
'Source': { S: message.source }
}
};
console.log('ITEM: %j', item);
// Insert dynamodb item
return dynamodb.putItem(item).promise()
.then(() => {
console.log('Item inserted');
})
.catch((err) => {
console.error(err);
});
}))
.then(v => callback(null, v), callback);
};
(The code can be found on the repository)
Deployment and test
Deployment using CDK
AWS Cloud Development Kit is a powerful framework that allows you to model and provision your cloud application resources using familiar programming languages. Our entire stack is configured and deployed using CDK. To keep it simple, we are using TypeScript as the programming language.
The CDK code below is fairly detailed and will create all the components for our stack:
import * as cdk from '@aws-cdk/core';
import * as sqs from '@aws-cdk/aws-sqs';
import * as dynamodb from '@aws-cdk/aws-dynamodb';
import * as lambda from '@aws-cdk/aws-lambda';
import { SqsEventSource } from '@aws-cdk/aws-lambda-event-sources';
export class EventSourcingDynamodbStack extends cdk.Stack {
constructor(scope: cdk.Construct, id: string, props?: cdk.StackProps) {
super(scope, id, props);
// Create queue
const queue = new sqs.Queue(this, 'queue', {
queueName: 'event-queue'
});
// Create lambda
const fn = new lambda.Function(this, 'fn', {
code: new lambda.AssetCode('resources'),
handler: 'lambda.handler',
runtime: lambda.Runtime.NODEJS_12_X,
functionName: 'event-to-dynamodb'
});
// Add lambda source
fn.addEventSource(new SqsEventSource(queue));
// Create dynamodb table
const sortKey = { name: 'Timestamp', type: dynamodb.AttributeType.STRING };
const table = new dynamodb.Table(this, 'table', {
partitionKey: { name: 'RequestId', type: dynamodb.AttributeType.STRING },
sortKey: sortKey,
tableName: 'event'
});
// Create GSI
table.addGlobalSecondaryIndex({
indexName: 'Type-Index',
partitionKey: { name: 'Type', type: dynamodb.AttributeType.STRING },
sortKey: sortKey
});
table.addGlobalSecondaryIndex({
indexName: 'Source-Index',
partitionKey: { name: 'Source', type: dynamodb.AttributeType.STRING },
sortKey: sortKey
});
// Grant write to lambda
table.grantWriteData(fn);
}
}
(The code can be found on the repository)
CDK significantly simplifys your stack definition/deployment - saving you from a big headache.
The commands below will deploy the whole stack:
cdk synth
cdk deploy
(make sure to have your AWS CLI configured)
Testing
In order to test the whole flow, we would need a Gateway that publishes a message to our SQS queue. For that, we will use AWS CLI to publish a message to the queue. The message content can be edited here.
aws sqs send-message --queue-url ${QUEUE_URL} --message-body file://test/message.json
Then check in the DynamoDB table to make sure the event was created correctly:

If it was not, you will need to check the Lambda's logs on CloudWatch.
Conclusion
Designing and deploying an entire event sourcing system on AWS is fairly straightforward when combining CDK and DynamoDB. By using AWS, the whole system is serverless, scalable, and enterprise ready! AWS CDK not only saves you time, but also provides more functionality in this use case than AWS CloudFormation. In addition, the AWS CDK supports TypeScript, JavaScript, Python, Java, and C#, allowing you to code in your preferred language.
All the working code featured in this blog post is available on this GitHub repository for your reference.
Need help using the latest AWS technologies? Need help modernizing your legacy systems to implement these new tools? Ippon can help! Send us a line at contact@ippon.tech.
