

Here at Ippon, we spend a lot of time thinking about solving problems for our clients. Sometimes we even think about solving problems before we meet a client with a problem. A recent example of that is our work in Customer Oriented Sentiment Analysis (COSA). In this blog post we will describe the problem we observed and how we tackled it, as well as the solution and implementation.
Problem statement
We all experience bad service or products at least somewhere and somehow yet we don’t always make it a point to address our dissatisfaction to the right authority. With the rise of social media, especially Twitter, more people tend to vent their thoughts and feelings about different experiences on social media. For a company, that presents opportunity and risk; one opportunity is to solicit competitor's clients, and the other is to identify current dissatisfied clients. The risk is one person can post a bad experience that can discourage a potential client from pursuing your brand.
Goal
COSA’s goal is to scrape tweets from Twitter for listed companies and associated words using the Twitter Stream API, and run a Machine Learning algorithm in real time to determine whether the tweet is a complaint or a compliment. We then provide a dashboard for the marketing team to identify the brands’ trends and take action.
Solution Process
On the Machine Learning aspect, we are using the Naive Bayes Classification model. It is a supervised learning based on the Naive Bayes’ Theorem, most effective when a problem does not have a correlation, meaning it assumes the presence of one occurrence is unrelated to another -- in our case, the features within the tweets and posts.
Using the Python TextBlob Machine Learning library, we trained the Naive Bayes Classifier then applied it to predict the sentiment analysis. The training data-set was obtained from Kaggle; it is of US Airlines tweets tagged with positive, negative and neutral sentiments. It has over 14,000 rows of tweets; we used only 2,000 rows to train the classifier and apply the trained classifier to 100 tweets to test its precision.
We first had to tokenize the dataset, remove the stop-words (words that are used commonly in English like “The”) and apply lemmatization (changing a word to its dictionary form with context, like changing runs to run) before we trained the model; the result was 82.66% accuracy.
The trained Naive Bayes Classifier is serialized, saved, packaged and then deployed on the Lambda function to produce the sentiments for the tweets ingested. If we come across a better Machine Learning algorithm, we will transition out of Naive Bayes.
Implementation
A team of three developers defined the epics, tasks and subtasks needed to develop and deploy this application into production. We leverage Jira to keep track of the project and conduct daily standup for team update. We used some managed services on AWS like DynamoDB and Lambda to ease the administration side of things as the developers were not engaged in this project full time. We were able to use Agile and Scrum, and demo a milestone every week to our internal product owner, Ippon USA Regional Director Wayne Huggins.
Architecture
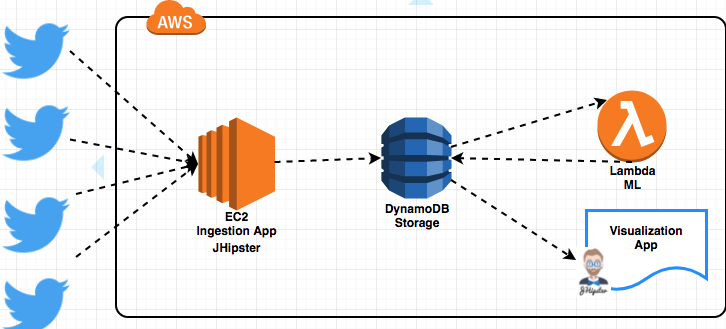
We provisioned an AWS server to ingest the tweets leveraging Java’s Twitter4J library; the tweets are stored on AWS’s managed NoSQL DynamoDB database.
Twitter is the data source where clients will tweet opinions of companies. Using a Java library - Twitter4J - we can subscribe to receive Tweets on specific keywords in real time.
Ingestion application
The ingestion application is a simple Java application to receive tweets as raw data from Twitter and write them to data storage, AWS DynamoDB. This application is deployed on an AWS EC2 instance and will leverage Twitter4j.
DynamoDB
DynamoDB is a NoSQL database similar to Cassandra, provided as a service by AWS. DynamoDB does not require any maintenance and can be easily scaled without any downtime. We have chosen to use DynamoDB to support the load of tweets written in real time and also to test its integration with the AWS Lambda service.
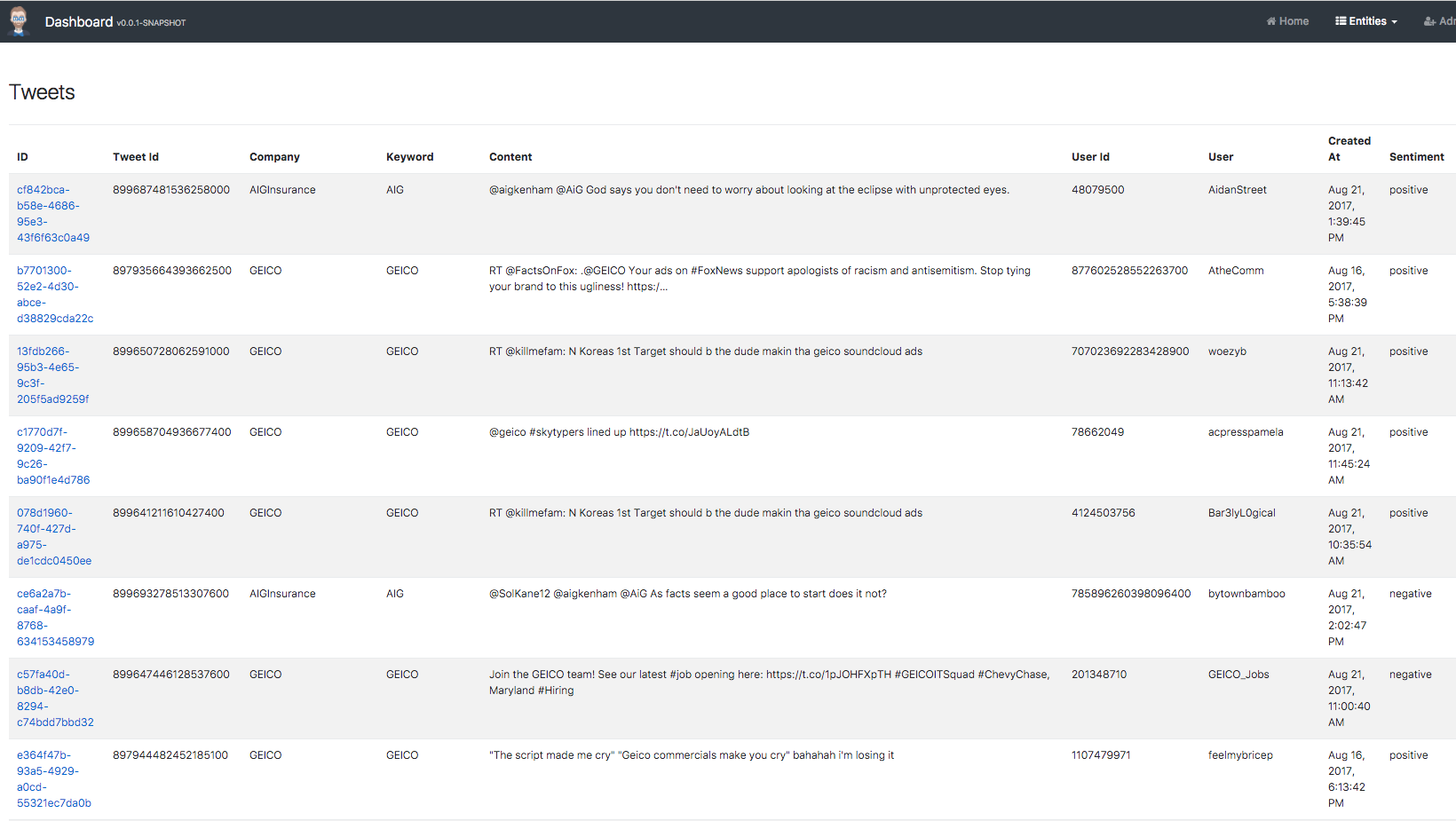
We store many attributes of the tweets ingested, including the company and keyword, along with the tweet and user’s name and the generated time.
Lambda
Trigger is a custom action that is designed to initiate when a specific event takes place. In this case it will be used to run a Python function that will read the tweet from DynamoDB, compute the sentiment and update the sentiment column on the database.
Lambda is a serverless compute service provided by Amazon Web Services (AWS) that will be initiated by the trigger to perform a specific task. It scales gracefully with no administration and no requirement for maintenance. It is very economical as we are not charged when a code is not running. Our application will run without any infrastructure management and without worry of capacity. Our Machine Learning code will be running on Lambda.
Visualization Application
The visualization application is a JHipster application; our open source application generator that creates Spring Boot and Angular projects. This application is deployed on the EC2 instance and displays the tweets and analytics stored in DynamoDB. Although JHipster does not offer a native support for DynamoDB, it can generate code for Apache Cassandra which is very similar to DynamoDB in its design. With minor changes to the code, we were able to migrate the code to use DynamoDB.
Business use cases
There are a number of potential business uses cases for this platform:
- It can be used to identify and reach out to clients dissatisfied with a service or product of a company, which can help increase brand loyalty and help gain market share percentage by reaching out to competitors’ clients at the moment when they are frustrated with competitors’ products and/or services.
- It can detect and identify new clients that are shopping for goods and services and are using social media to gather information and recommendation.
- It can be made to respond to a Twitter user that complains about a company instantly, increasing the chances of retention or acquiring a new client.
- It can help a company strengthen its weakness by analyzing complaints and negative tweets, as not all clients will willingly issue a compliment or complaint to a company directly and freely as they would on social media; when people are behind a computer and not looking someone in the eyes, they are less intimidated to be honest.
What can this project turn into
Marketing
This platform can easily turn into a great marketing tool. It can be leveraged to keep an eye on the competition. Every company needs to know the strengths and weaknesses of competitors in order to gain market share. Identifying and appeasing a frustrated competitor's client can be a golden opportunity for a company.
On the other hand, it can also help a company identify its own dissatisfied clients and immediately engage in a dialogue, compensate mistakes and make corrections. That will help companies boost their client engagement level. It can also help companies analyze the geographical landscape of their clients and competitors’ clients, which can aid in decision-making. This also helps to keep up-to-date and adjust to the shifting trends of the market.
Once a company uses this platform and accumulates a wealth of historical tweets over a period of time, it can be analyzed to see what a company’s strengths and weaknesses are and improve accordingly.
Facebook Graph API
We are also exploring the Facebook graph API to stream Facebook status that contain keywords associated with a company and apply sentiment analysis on it.
Client Prediction
In the future, this platform can also grow into a potential client prediction by analyzing the tweets and statuses. By analyzing our happy client’s tweets and statuses, we can compare it to other Twitter and Facebook users that have similar patterns to solicit as a client; or avoid undesirable clients that are good for business.
Application Growth
One component that we feel is missing in this project is continous integration and continuous delivery (CI/CD). The project has been designed to handle a high turnover of developers. New people who will contribute to the project will be continuously onboarded and ofboarded. Therefore, the team would like to design a good method for continuously integrating new features into the application and a quick and easy way to deliver those new features to a production ready version of the application.
Summary
In today’s market, innovation is not only good for growth it is a necessity for survival. Successful companies that were reluctant to innovation have lost market share and some even went bankrupt. The beauty of the sentiment analysis platform is that it displays the trend of perception of a company’s brand, service and/or goods.
For companies, perception is determinant of growth or failure. Social media is an advertising platform with 2.3 billion active users; for companies that provide good products and/or service, it is a great medium to grow brand awareness and market share. All marketing specialists agree, word of mouth is a form of advertisement that carries trust as it comes from the client.
Keeping an eye on a company’s word of mouth has been made possible due to social media. Our platform is being designed to leverage Twitter and Facebook to track current trends, enabling companies to make better business decisions. It also enables analysis of historical tweets and posts.
