

GraphQL is a modern approach to client-server communication and aims to improve the way developers build web applications. According to its name (QL = Query Language), it is a data query language for APIs, strongly typed, and a runtime environment that processes these requests.
The first version of this language was designed by Facebook in 2012 and released publicly in 2015. Many specifications were published, up to the last one dating from October 2021, which includes all of its features. Multiple implementations of this specification are available in several languages, both on the client and server sides.
Today, GraphQL is mentioned more and more frequently as the alternative solution to REST. But is this really the ideal solution? What are the main characteristics of the language? In this article, I am going to introduce its core features through Apollo, one of the libraries implementing GraphQL. But first, let us take a closer look at the difference between the way REST and GraphQL works.
Compared to REST
The REST formalism forces the client to bend to the existing server-side endpoints to retrieve the resources it needs, and so often calls multiple endpoints to fetch whole data (or more data than required). With GraphQL, one call is enough to do so: the client will make this single call to the GraphQL server, which will be in charge of retrieving all requested resources.
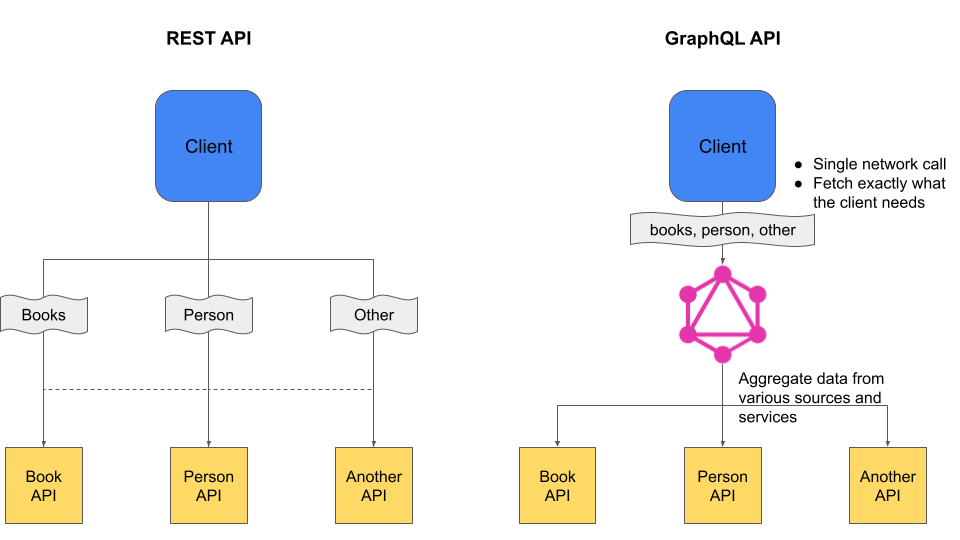
Thanks to GraphQL, you will be able to get many resources with only one request (composite pattern), these resources can be stored in different ways (API, database, file, etc.). This prevents over-fetching (seeking too much data) and under-fetching (seeking less than enough data). For this reason, calls between the client and the server are faster and lighter.
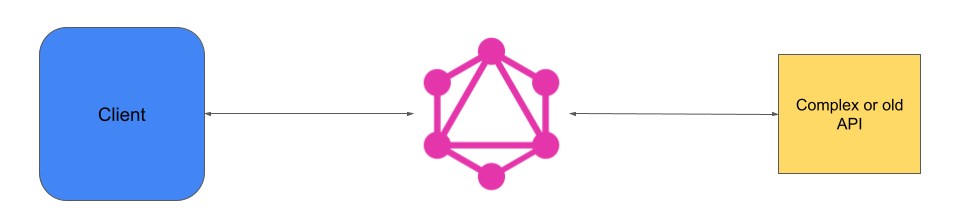
Furthermore, GraphQL may also be used to implement other design patterns. For instance, we can simplify the use of a complex API by adding a GraphQL bloc between the client and this API (facade pattern). Similarly, it is possible to include a GraphQL layer to enrich an old API with a new feature, for example, an authentication layer (proxy pattern).
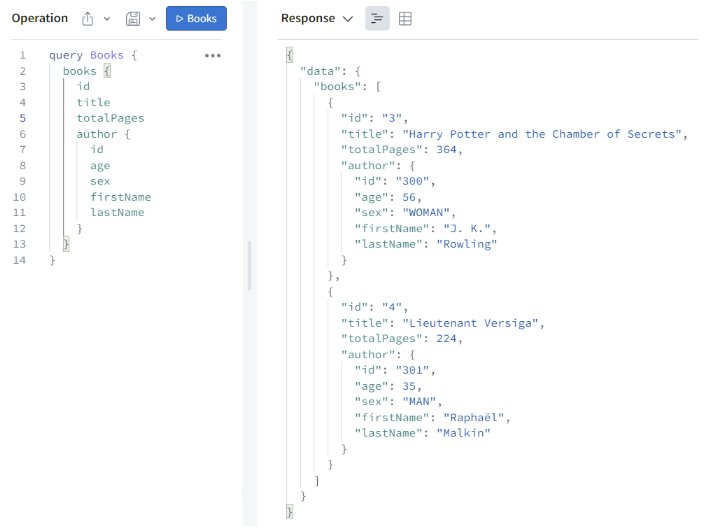
Here’s what a request and a response from the GraphQL server actually looks like:
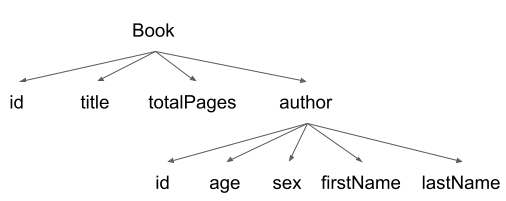
Every GraphQL response is a JSON map and represents a graph, where the objects are linked together. These links can be represented by the following graph:
Below is a diagram summarizing how GraphQL works with these specific keywords. We will look into it closely throughout the rest of this article:
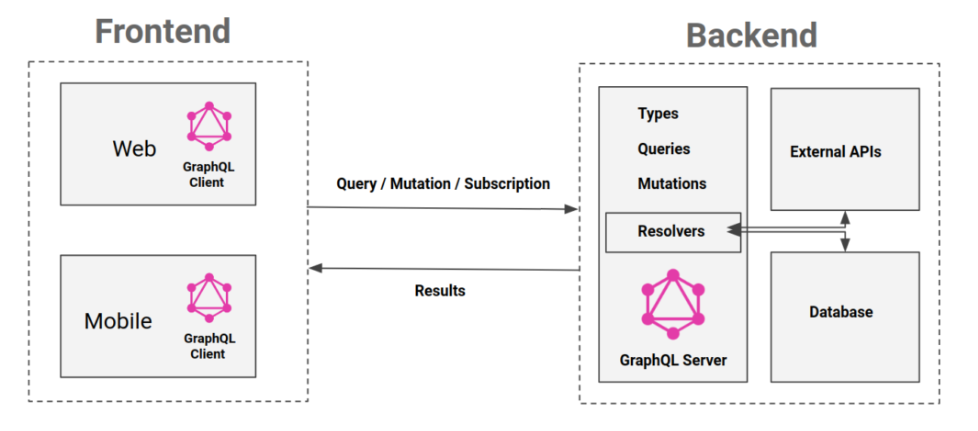
Interlude
Before going any further, it is necessary to have an overview of the data sources on which the following examples will be based. By “data sources”, I mean all data that comes from external APIs or databases. I will use a list of books and films that each refer to a person via its identifier (an author for a book, a director for a film, etc.). These lists are intended to simulate the response of external APIs (e.g., media API and people API).
const bookData = [
{
id: 3,
title: "Harry Potter and the Chamber of Secrets",
author: 300,
totalPages: 364,
},
{
id: 4,
title: "Lieutenant Versiga",
author: 301,
totalPages: 224,
},
];
const movieData = [
{
id: 100,
title: "Titanic",
director: 10,
runTime: 160,
},
{
id: 101,
title: "Forrest Gump",
director: 11,
runTime: 140,
},
];
const mediaData = [...bookData, ...movieData];
const authors = [
{
id: 300,
firstName: "J. K.",
lastName: "Rowling",
dateOfBirth: "1965-07-31T00:00:00.000Z",
sex: "WOMAN",
},
{
id: 301,
firstName: "Raphaël",
lastName: "Malkin",
dateOfBirth: "1987-03-01T00:00:00.000Z",
sex: "MAN",
},
];
const directors = [
{
id: 10,
firstName: "James",
lastName: "Cameron",
dateOfBirth: "1954-08-16T00:00:00.000Z",
},
{
id: 11,
firstName: "Robert",
lastName: "Zemeckis",
dateOfBirth: "1951-05-14T00:00:00.000Z",
},
];
const personData = [...authors, ...directors];
Schema
Schema is the core feature in GraphQL. The schema defines a hierarchy of types with fields that are populated from back end data sources. This schema also specifies exactly which queries and mutations are available for clients to execute. Possible structures include:
- Scalar type
- Int
- Float
- String
- Boolean
- ID (a unique string value, especially for cache management)
- Object (Query, Mutation, Subscription)
- Input (enables complex objects to pass as parameter of queries or mutations)
- Enum (defines a set of allowed values)
- Union (represents several return types for an object)
- Interface (shares a set of fields between multiples types)
This is how we can represent our business objects in a GraphQL schema in comparison to our data sources:
type Book {
id: ID!
title: String!
totalPages: Int
author: Person
}
type Person {
id: ID!
firstName: String
lastName: String
age: Int
sex: Sex
}
enum Sex {
MAN
WOMAN
OTHER
}
We can apply additional type modifiers to objects in schema by providing validation (define a mandatory field) or specifying lists. Let us have a look at all the possible combinations with the String type, for example:
- String : string can be null
- String! : non-null string
- [String] : List can be null, containing strings that can be null
- [String!] : List can be null, containing non-null strings
- [String!]! : non-null List containing non null strings. An empty string is valid.
These rules will be checked by the GraphQL server and it will trigger a validation error in case of non-compliance.
In addition, GraphQL has an introspection function, querying the server to know information about its schema. This allows the client to have a description of all objects present on the server and all possible operations with associated arguments. It is therefore a type of automatic documentation that is sent back, which allows the client to easily discover the available features.
Resolver
A resolver associates a query or an action to each field of the schema to determine how the data will be processed or retrieved.
const resolvers = {
Book: {
author(parent) {
return personData.find((a) => a.id === parent.author);
},
},
Person: {
// Compute the person's age from date of birth
age(parent) {
var diff = Date.now() - new Date(parent.dateOfBirth).getTime();
var age = new Date(diff);
return Math.abs(age.getUTCFullYear() - 1970);
},
},
};
In this example, we search for the corresponding Person object in the personData list using its id to get back the data of an author attached to a book.
Also, through age resolver of the object Person, the input data (a birthdate, e.g. 1987-03-01T00:00:00.000Z) is converted into years to match what we want as an output (the person’s age, so 35 years old in this case).
Note that the other fields of the Book (id, title, totalPages) or Person (id, firstName, lastName, sex) objects have no resolver. This is not a mistake. There are indeed default resolvers that automatically map the datasource with the same name as the field name defined in the schema. For instance, the JSON input returns a title field for the Book object, and the Book object schema has a title field, so GraphQL is able to do the mapping on its own. This would be the same as writing the following resolver:
Book: {
...
title(parent) {
return parent.title
}
},
In addition, resolvers define all possible operations that the server may receive: query, mutation and subscription.
Query
A query is used to fetch values from the GraphQL server: it is therefore a data reading operation. The payload return is in JSON format and different queries can be executed in parallel. These queries are defined in the schema and processed in the resolver.
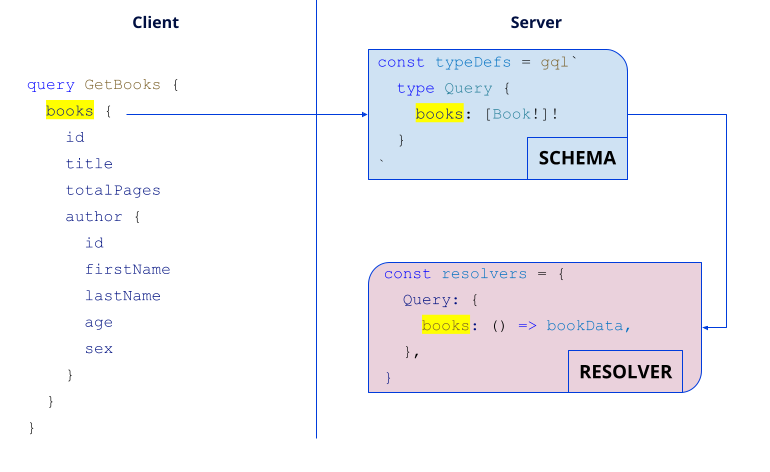
GraphQL links the client to the server via the name of the method you aim to call (here, books highlighted in yellow). Once the request has been received, the server will check if it exists in the schema under the Query type and if it has the correct parameters and return type (here, no parameter, but a list of Books in output).
The server then searches in the resolver for the associate function under the Query field, but only if the request is valid. Finally, the resolver returns the data and reorders it to match exactly the fields of the query in the requested order. In our example, the resolver directly returns bookData, the book’s list in JSON format.
Interface
Interfaces are abstract types that allow fields to be shared between different objects. Each object implementing an interface must have at least similar fields, and others if necessary.
Let’s take the previous schema with the Book type. We can add a Movie type and a Media interface, so Book and Movie share common fields (id and title) through the implementation of the Media interface.
interface Media {
id: ID!
title: String!
}
type Book implements Media {
id: ID!
title: String!
totalPages: Int
author: Person
}
type Movie implements Media {
id: ID!
title: String!
runTime: Int
director: Person
}
Alternatively, multiple interfaces can be implemented using the following syntax:
type MyObject implements Interface1 & Interface2 {
…
}
Now imagine we wanted to fetch all the Media objects, by retrieving both common and specific fields of the objects implementing this interface.
How does the server know the difference between a Book and a Movie?
Firstly, the query must be declared in the schema and defined in the associate resolver (such as the books’ query). Next, the special function __resolveType provided by apollo-server will be included in the resolver of the Media object. This function will allow us to define the type of implementation that will be returned according to the fields available in the object. In the case of the author field being present, then a Book will be returned. Otherwise, if the object has a director field, a Film will be returned.
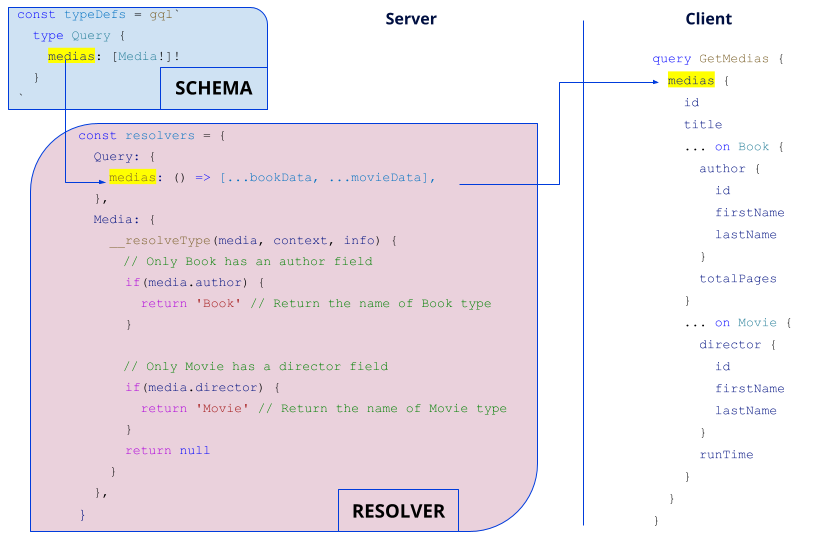
At last, the client-side query will use the … on Book or … on Movie syntax to retrieve the specific fields to these objects. This notation is called an inline fragment.
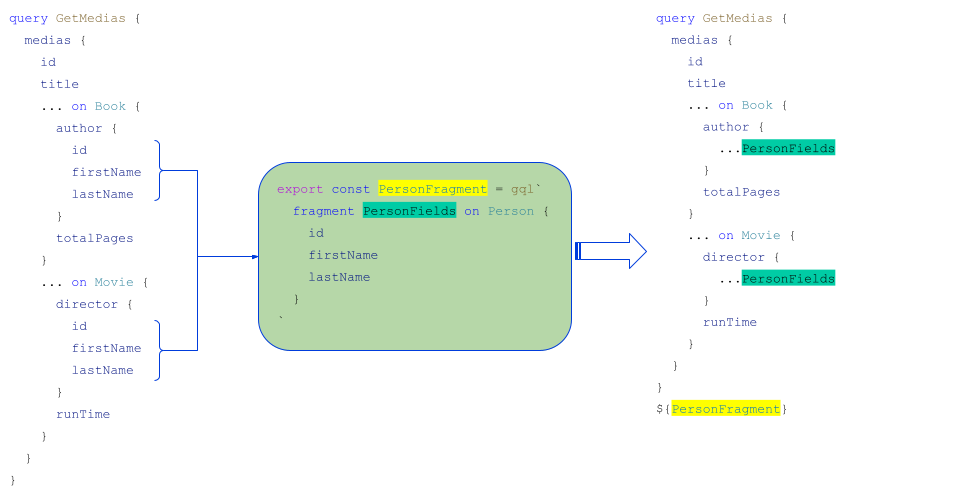
Fragments
In addition to inline fragments, there are fragments that allow sharing pieces of query in the client-side. In the previous example, the author and director objects have the same id, firstName and lastName fields. These fields could be gathered in a PersonFragment fragment together:
Mutation
Mutations relate to all data changes: add, edit, delete. In the same way as queries, the mutation must be defined in the schema (in the Mutation type) and implemented in the associate function of the resolver (in Mutation object). It can also return an object, which can be useful to retrieve the state of the object updated by this mutation. However, unlike queries, mutations are performed in series, one after the other.
A book's addition looks like this:
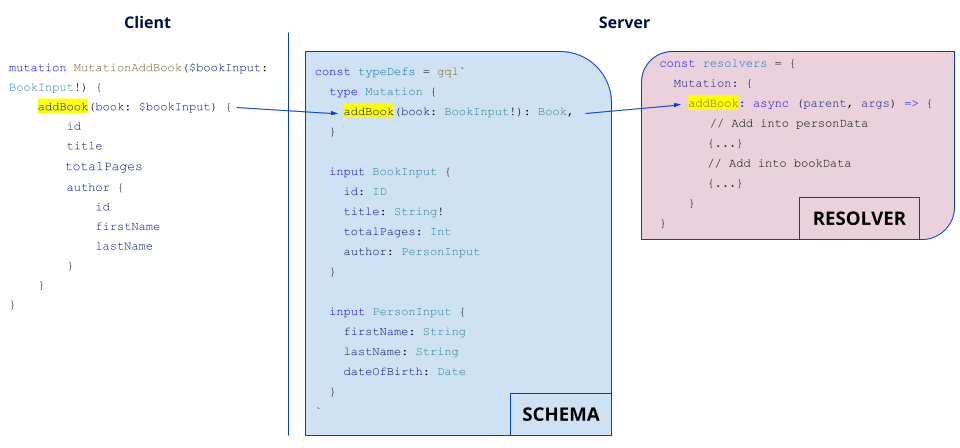
As in the example, input items can be employed (BookInput and PersonInput), where each field stands for a parameter, which may be convenient if you want to modify a complex object instead of modifying fields one by one.
In the same way, this is the process of a book's modification:
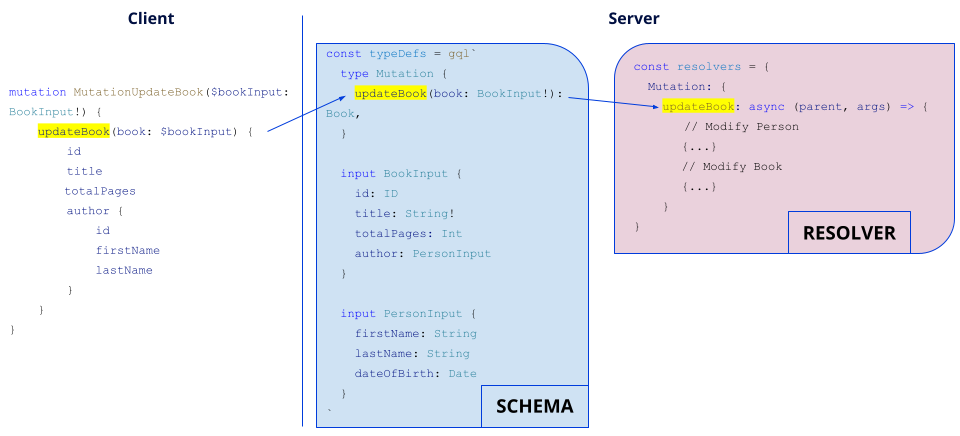
Subscription
Subscriptions are the third family of possible operations in GraphQL. Like query, subscriptions specify a set of fields to be delivered to the client. But instead of immediately returning an answer, a result is sent every time an event happens on the server after the client subscribes to it. Even though they are less common than queries and mutations, they can be used to be notified in real time of a change in server-side data, such as the arrival of a new message in a chat application.
If we go back to our example, we can add a subscription in a MediasCounter graphic component that would subscribe to the event of adding a book and then increment a counter. Here’s what would happen schematically:
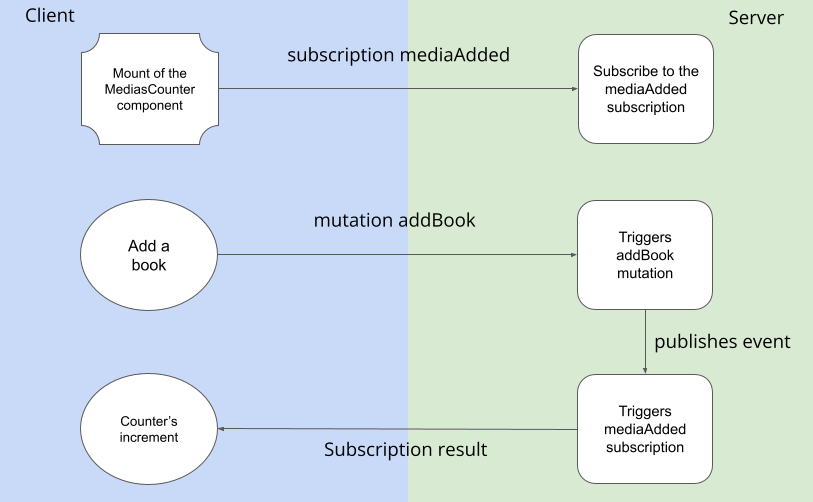
In the same manner as the definition of queries and mutations, the subscription must be declared in the schema via the Subscription type and the associate function must be defined in the resolver, into the Subscription object.
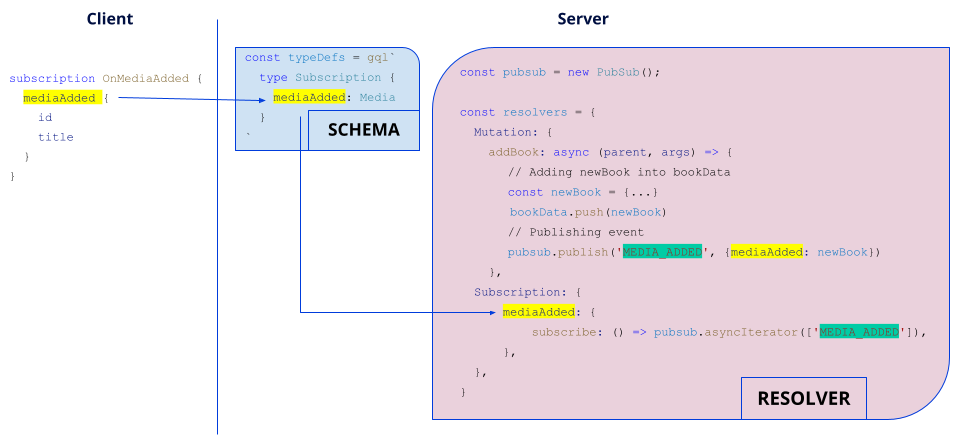
The notable difference between queries/mutations and subscriptions is the use of a publish/subscribe tool (here, PubSub included in graphql-subscriptions library). This kind of tool allows you to subscribe to (pubsub.asyncIterator(['NOM_EVENT'])) and publish an event (pubsub.publish('NOM_EVENT', {mediaAdded: newBook})).
The publication of a MEDIA_ADDED event is added into the addBook mutation. A “notification” will be sent to all subscribers who will be able to respond, such as our MediasCounter component by incrementing a counter for the addition of books.
Conclusion
This introduction to GraphQL has reached the end. I have tried to address the most important features through code examples to give a more concrete overview of how GraphQL works.
To sum up, GraphQL optimizes requests between the client and server by requiring the exact fields needed. This allows us to reduce the size of the network frame, which can be ideal in a mobile environment, for example. Another important point is the aggregation of multiple datasources, which is useful in an architecture with a multitude of microservices. Finally, thanks to its introspection system, the client can easily discover the API and understand its modus operandi with the auto-generating documentation.
The learning curve can certainly be difficult due to the new concepts and the multiplicity of files, both on the client side and on the server side.
All in all, GraphQL is a solid alternative/complement to REST and occupies a growing place in architectures that communicate with APIs. Other points remain to be addressed, such as cache management, error management, schema stitching, or the various debugging tools
Webography
GraphQL | A query language for your API
