

Summary
Do you find yourself lost in an endless sea of data tools? Are you new to the world of data and unsure where to dive in? Are you an experienced data professional, always on the lookout for new ways to navigate the ever-changing tides of data? Either way, this blog series is here to help. Throughout this series we will provide an introduction to the data stack, highlight technologies useful for ingestion, transformation, load, and orchestration, and explain how this combination of tools can build a robust and scalable data infrastructure that can take your business to the next level.
The Data Stack & Tool Overview
The data stack is a collection of tools and technologies that work together to enable efficient and scalable management of data. In this series, we will review a stack organized around four key components: ingest, transform, load, and orchestrate. The first step in the data stack is the ingest phase, where data is pulled from various sources and made available for further processing. This is where tools like Fivetran come into play. Once the data has been ingested, the next step is to transform it into a usable format for analysis. This is where we'll cover tools like dbt. Once the data has been transformed, the next step is to load it into a data warehouse, like Snowflake. Finally, the orchestrate phase involves scheduling and automating the data pipeline, and is where we'll discuss tools like Airflow. Overall, the data stack is a powerful set of tools that provides a comprehensive framework for managing data at scale, from ingestion to analysis. By leveraging these tools, data professionals and engineers alike can create efficient, reliable, and scalable data infrastructures that can help businesses thrive in the rapidly evolving world of data.
Ingestion
Ingestion, the first component in our stack, refers to the process of extracting data from various sources and bringing it together for further processing. Ingestion tools can enable data engineers to quickly and easily connect to a variety of sources, such as databases, SaaS applications, cloud storage services, and other APIs, and synchronize the data into a single space. This process can include several key steps, including configuring a connection to the data source, defining the data to be extracted, and scheduling the data sync frequency. Ingestion tools provide an advantage here through their user interfaces, simplifying the data integration process and eliminating the need for manual data ingestion, which can be time-consuming and error-prone. By leveraging ingestion tools, data engineers can ensure that data is available and ready for processing. Additionally, ingestion tools can help to maintain data accuracy, completeness, and consistency, ensuring that data is reliable and trustworthy for businesses to transform for their use cases. Overall, the ingestion phase of the data stack is critical for establishing a reliable and efficient data infrastructure from square one, enabling businesses to easily extract and integrate data from where it can be best used.
Fivetran
Let's start with Fivetran. Fivetran, a popular integration platform, simplifies the process of data ingestion by automatically collecting and loading data from various sources into a centralized location for further processing. Fivetran acts as a dedicated courier, constantly on the move to collect data from a wide range of sources. As the trusted messenger of the data stack, it is responsible for collecting and delivering data from various sources. Overall, it acts as a liaison between different systems and users, ensuring reliable data delivery.
Pros:
- Easy to set up and use
- Designed to be easy to use, it requires minimal technical knowhow
- A user friendly interface allows quick connection and data load
- Wide range of integrations
- Supports over 150 pre-built connectors to sources such as databases and marketing tools
- Easy connection, no need to design a data stack with pre existing constraints
- Automated data ingestion
- Automatically fetches and loads data from sources on a predefined schedule
- Ensures data is up to date and ready for future analysis
- Real time monitoring
- Provides real time monitoring and alerts
- Facilitates smooth data flow
Cons:
- Limited transformation capabilities
- Primarily designed for ingestion
- Out-of-box transformations are limited, for more advanced transformation it is recommended to use additional supporting technologies, like dbt
- Limited flexibility
- While it can support a wide range of integrations, it may not be able to support every custom integration that an organization needs
- Cost
- Charges based on the number of data sources and the amount of ingested data
- May be a challenge for organizations with a large number of high volume data sources
Usage Example: From S3 to Snowflake, with Fivetran!
To demonstrate Fivetran's ingestion capabilites we will walk through a scenario, similarily outlined here, where data is ingested in three, relatively simple, steps.
- Connect Fivetran to your target source to ingest to (in this case, Snowflake)
To establish a connection we can utilize Partner Connect, within Snowflake, to connect to Fivetran.
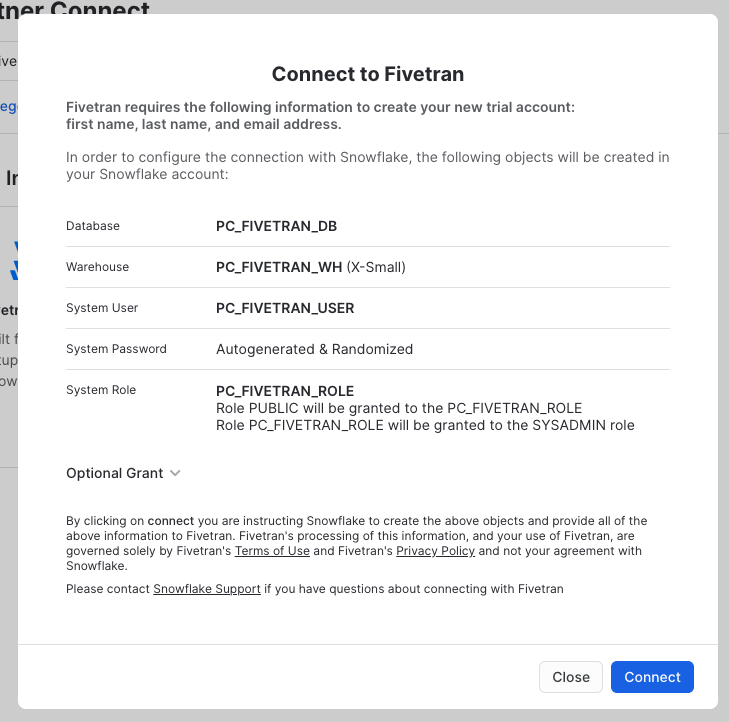
Notice that all the components needed (database, warehouse, user, role, etc.) are created automatically within Snowflake.
Note how Fivetran automatically sets Snowflake as our destination source.
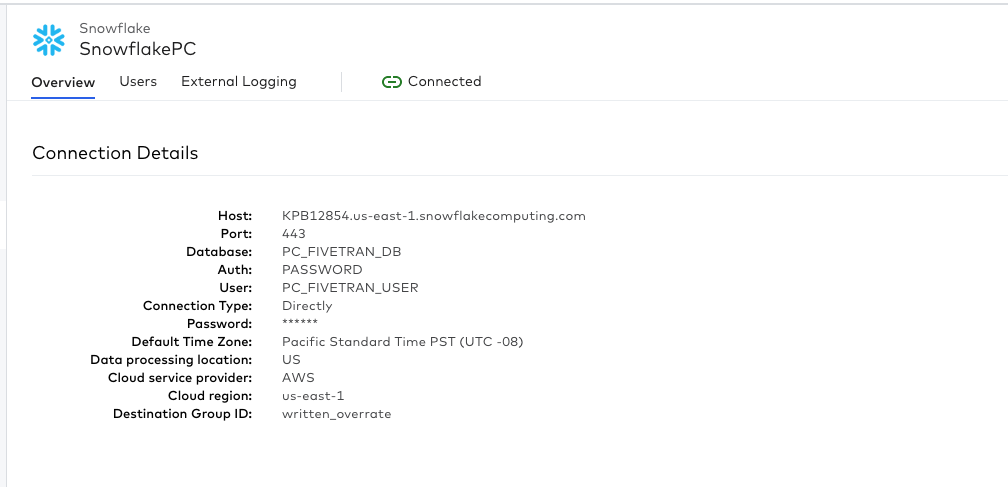
Finally, we can see that Fivetran auto-creates our connection profile for our destination.
- Connect your source to ingest from.
We can now connect to our ingestion source. We can do this within Fivetran's interface, which offers many connector types to technolgoies like S3, GCP, Instagram Business, and more.
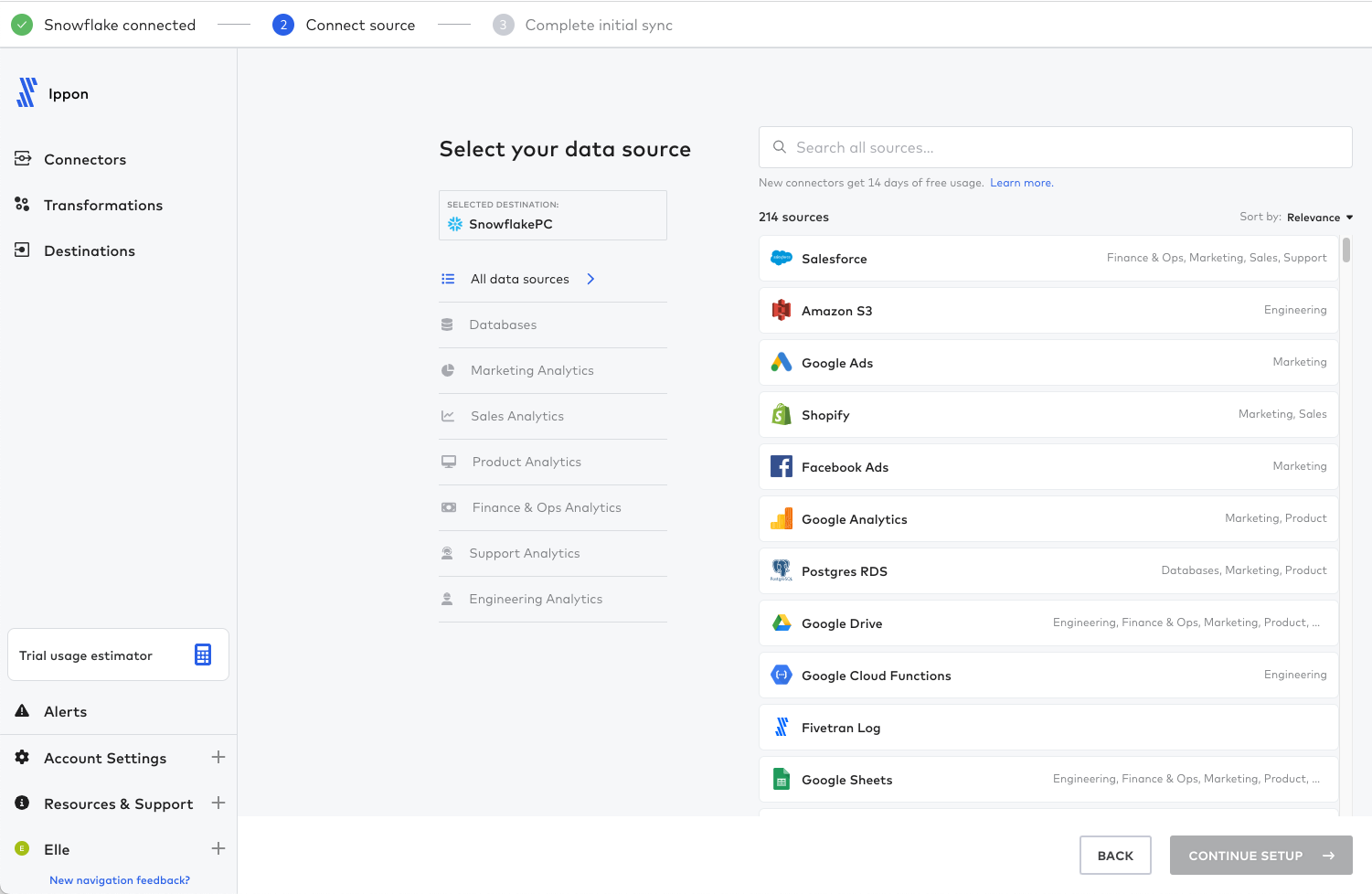
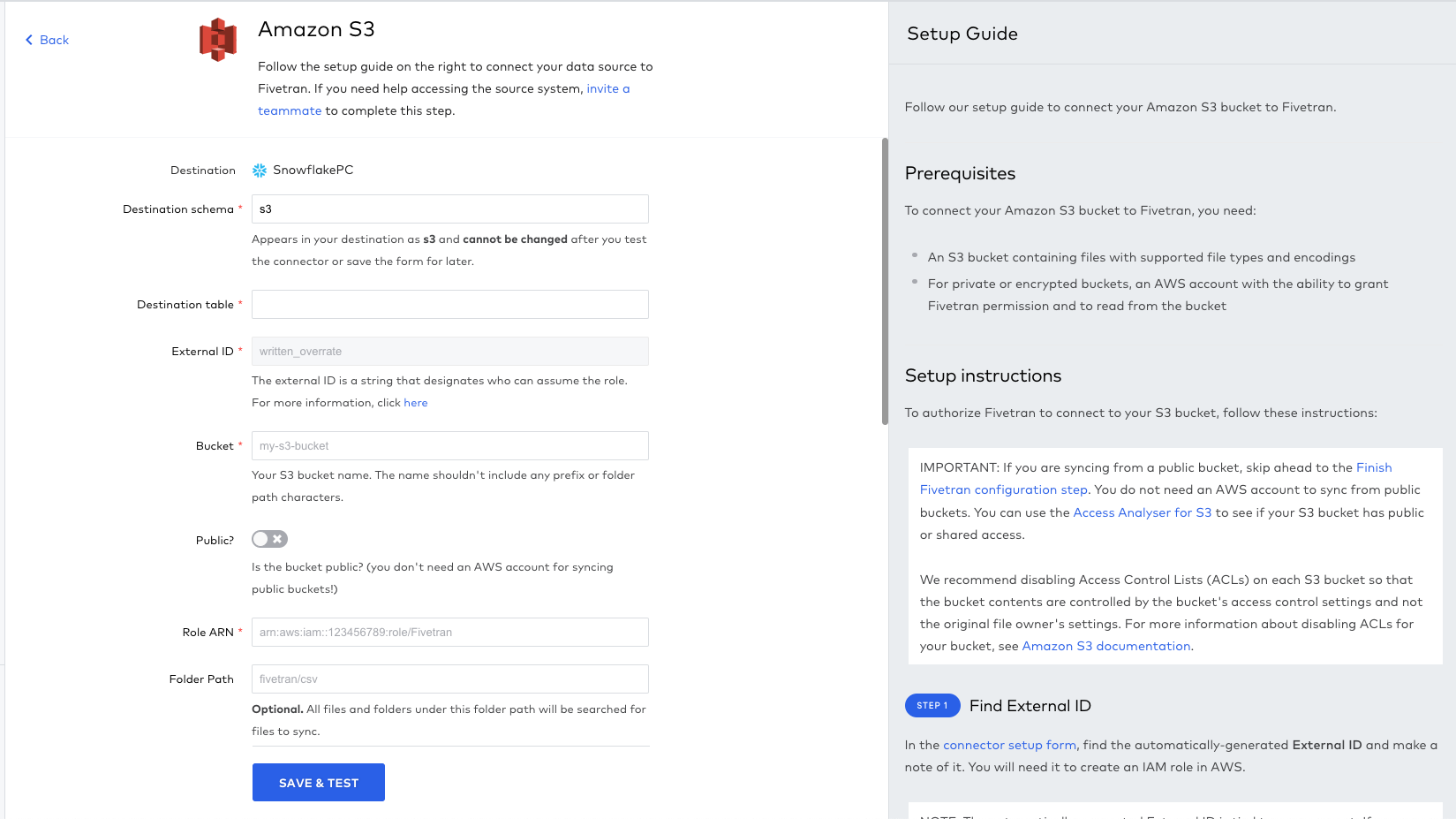
After selecting the correct connector type, completing the required fields, and following along with Fivetran's easy-to-understand setup guides if need be, we can select 'save and test'. Here is an example of what a connector would look like, in this case S3.
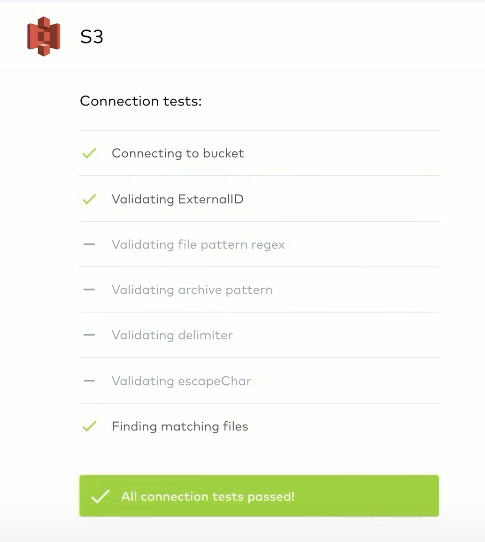
If the tests are successful, ingestion can begin.
- Sync'd
Depending on the data's source and volume, it may take a moment for syncing to complete. Once finished, the ingested data is now ready and can be processed for further use in the next stage of the data stack!
Conclusion
We’ve discussed the basics of the data stack, the ingestion phase, and the role Fivetran can play within a business' data infrastructure. In the upcoming post in this series we'll progress to the transformation phase.