
With more than 300 million active users, Twitter is still one of the more optimal platforms to provide efficient and accurate real-time news. The SMS of the Internet is also one of the best social networks and is used by a plethora of developers, which makes it a prime source of tech information.
With #Hashtags, Twitter found a way to let its users group posts together and follow specific topics in order to get immediate updates. My favorite tool to give you the best Twitter experience is TweetDeck, in which you can define your own custom dashboard in order to fulfill all your needs. My favorite "column" is the Trending one and my guilty pleasure is to check it multiple times a day to always be aware of what is happening (even if sometimes I am quite surprised of what is currently trending...).
The goal of this blog is to explain how cheap and easy it is to save and analyze what is trending on Twitter using services provided by AWS. There are several use cases that can be done once you have this architecture up and running. One, for example, would be to notify you if a specific topic is trending in order to avoid missing something new!
AWS Services and Architecture
The beauty of AWS is that it provides us all the services that we need in order to build our Twitter analytics platform. That saves us time and headaches of hosting and configuration, and instead allows us to focus on the fun parts of this project.
The architecture leverages mature AWS services and the flow is pretty simple, here is a diagram to summarize:
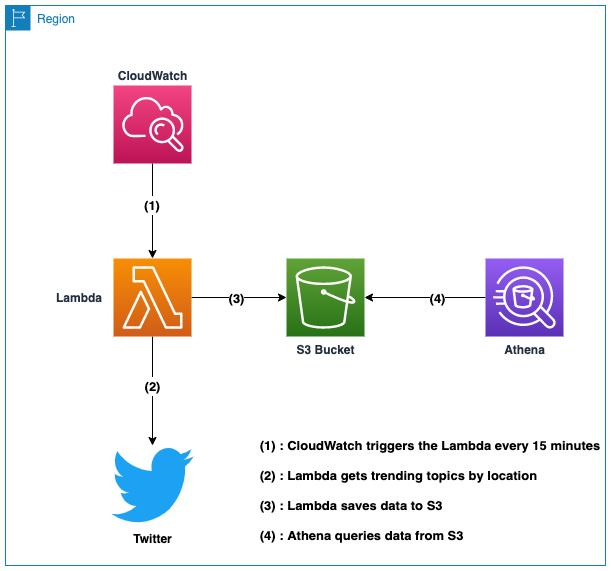
A future feature that could be added would be the ability to implement an event-driven system that will notify other components if a specific topic is trending. You could, for example, receive a notification on your phone via text or an email when a defined topic is trending in your location. The Lambda would be in charge of checking if one of the trending topics is part of a user-defined list and then push a message to AWS SNS.
Deployment using AWS CDK
AWS Cloud Development Kit is THE framework that you need to use to define your AWS cloud infrastructure in code. Out of the five supported languages (JavaScript, TypeScript, Python, Java or .NET), you can pick your favorite, and its simplicity will save you time. I recommend using TypeScript since the CDK team prioritizes it and you will also have more examples available on this GitHub repository.
For this blog, I decided to use Python since I'm more familiar with it and tend to prefer it over TypeScript. I recommend reading this CDK tutorial in order to have all the necessary tools installed.
Lambda
In order to use the Twitter API, you will first have to create an application in order to acquire secrets/tokens. You can follow the instructions here on how to create a Twitter application that will use the API.
The Lambda code below is pretty straightforward since its task is to call the Twitter API and save the result to S3.
import datetime
import json
import os
import boto3
import twitter
s3 = boto3.resource('s3')
def main(event, context):
# Create Twitter API instance
api = twitter.Api(consumer_key=os.environ['CONSUMER_KEY'],
consumer_secret=os.environ['CONSUMER_SECRET'],
access_token_key=os.environ['ACCESS_TOKEN_KEY'],
access_token_secret=os.environ['ACCESS_TOKEN_SECRET'])
# Get top 10 trending topics for a specific location
trends = api.GetTrendsWoeid(os.environ['WOEID'])
# Format to have a JSON document on each line
body = '\n'.join(list(map(lambda trend: json.dumps(trend._json), trends)))
# Save to S3 with a key like "2020-07-23 05:25:08"
key = datetime.datetime.now().strftime('%Y-%m-%d %H:%M:%S')
s3.Bucket(os.environ['BUCKET']).put_object(Key=key, Body=body)
return {
'message': 'UPLOAD OK'
}
Stack
The benefit of CDK is that you can define your whole infrastructure with merely a few lines of code and have all the permissions configured. Below you have the code that creates the S3 bucket, the Lambda, and set a rule to execute the Lambda every 15 minutes. The Lambda's environment variables are used to pass the credentials, the S3 bucket and the WOEID (the location used to get the trending topics from). New York is used for this blog but you an replace the WOEID with one of your choice, here is the list of what is available.
from aws_cdk import (
aws_s3 as s3,
aws_events as events,
aws_lambda as lambda_,
aws_events_targets as targets,
core,
)
class TwitterTrendsStack(core.Stack):
def __init__(self, scope: core.Construct, id: str, **kwargs) -> None:
super().__init__(scope, id, **kwargs)
bucket = s3.Bucket(self, 'tlebrun-playground')
handler = lambda_.Function(self, 'TrendsHandler',
runtime=lambda_.Runtime.PYTHON_3_8,
code=lambda_.Code.asset('resources'),
handler='trends.main',
environment=dict(BUCKET=bucket.bucket_name,
CONSUMER_KEY='',
CONSUMER_SECRET='',
ACCESS_TOKEN_KEY='',
ACCESS_TOKEN_SECRET='',
WOEID='2459115')
)
bucket.grant_read_write(handler)
events.Rule(self, 'RuleHandler',
rule_name='Twitter_Trends_15_Minutes_Rule',
schedule=events.Schedule.rate(duration=core.Duration.minutes(15)),
targets=[targets.LambdaFunction(handler)])
The project is available at this GitHub repository in case you want to clone it.
Data Visualization with AWS Athena
Database and table creation
Once you have the Lambda running for few days, you will be able to view the data in a few minutes using AWS Athena. Athena lets you query your data stored on S3 without having to set up an entire database and having batch processes running. You can create a new database using the AWS Glue service using the console and then create the table using the Athena service.
-- Create table
CREATE EXTERNAL TABLE
IF NOT EXISTS twitter.trend
(
`name` string,
`url` string,
`promoted_content` string,
`query` string,
`tweet_volume` bigint
)
ROW FORMAT SERDE 'org.openx.data.jsonserde.JsonSerDe'
WITH SERDEPROPERTIES (
'serialization.format' = '1'
) LOCATION 's3://S3_BUCKET/'
TBLPROPERTIES
('has_encrypted_data'='false');
The query above will create the table; the name of the fields are the same as the one from the JSON stored on S3. Don't forget to replace S3_BUCKET with the actual bucket containing the files.
Querying the table
Here are a few queries to showcase what can be done with Athena:
Select latest trends
SELECT
date_parse(substr("$path", 61), '%Y-%m-%d %H:%i:%s') as date,
tweet_volume as volume,
name,
url,
query,
promoted_content as promoted
FROM twitter.trend
WHERE tweet_volume > 0
ORDER BY date DESC;
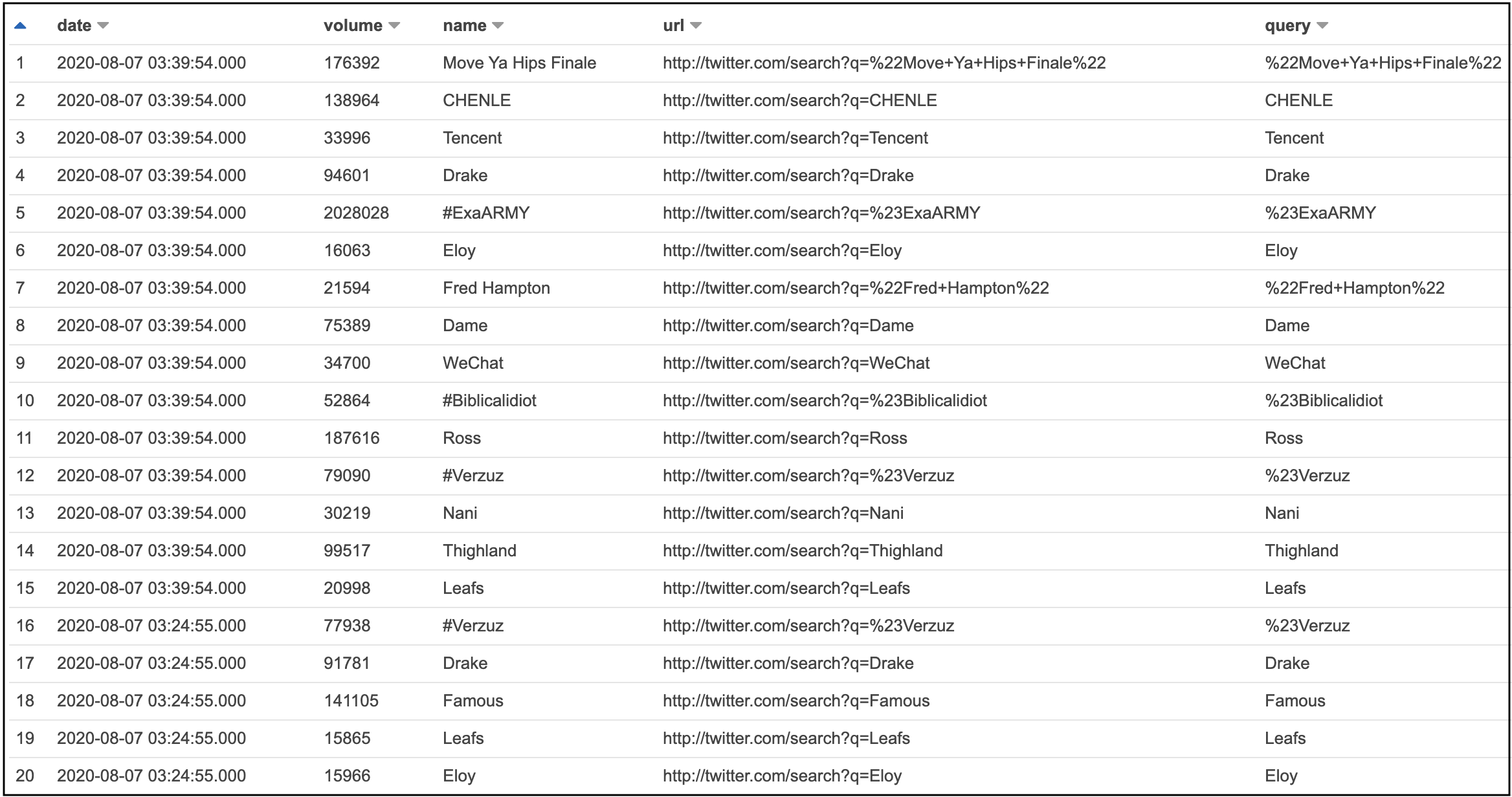
Select trends with highest volume
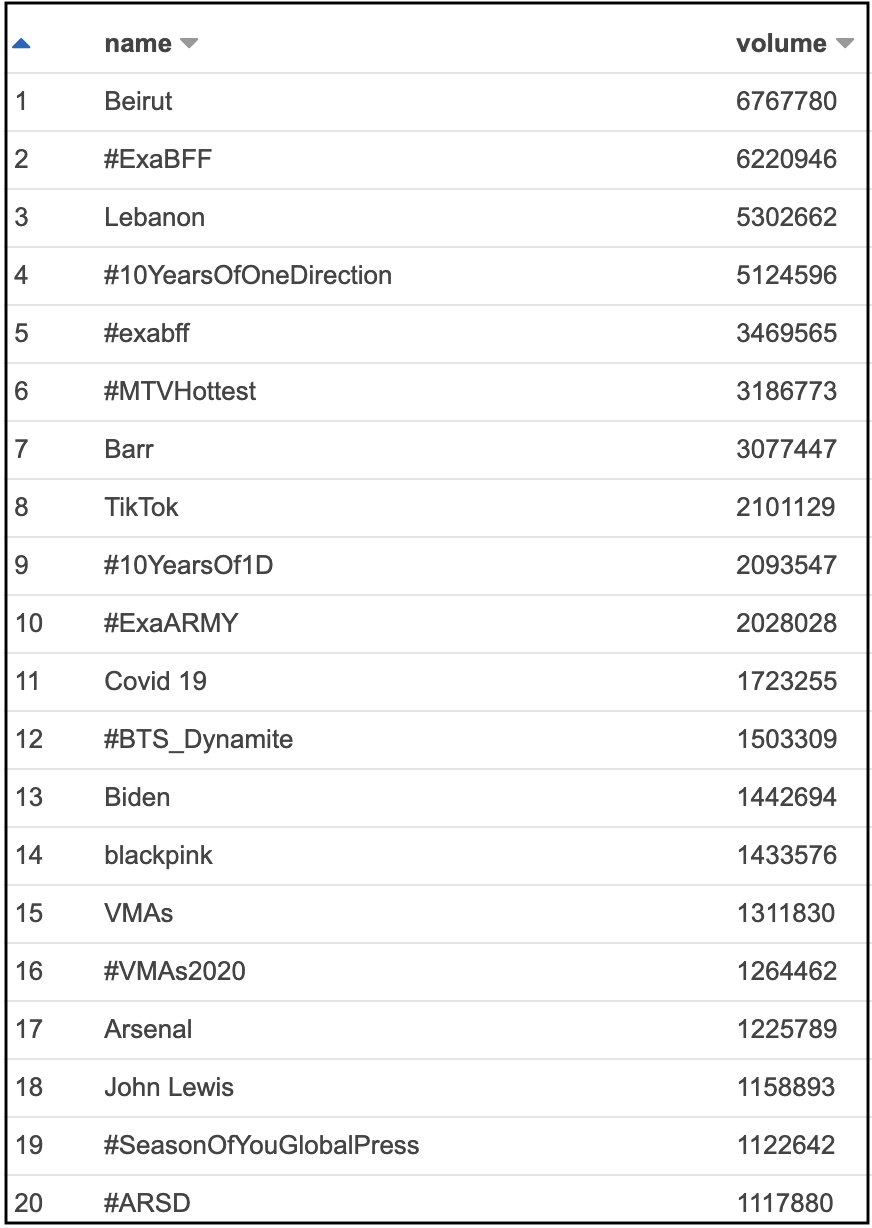
SELECT
name,
MAX(tweet_volume) as volume
FROM twitter.trend
GROUP BY name
ORDER BY MAX(tweet_volume) DESC;
Select trends with highest occurrence
SELECT *
FROM (SELECT name, COUNT(name) as count
FROM twitter.trend
GROUP BY name)
ORDER BY count desc;
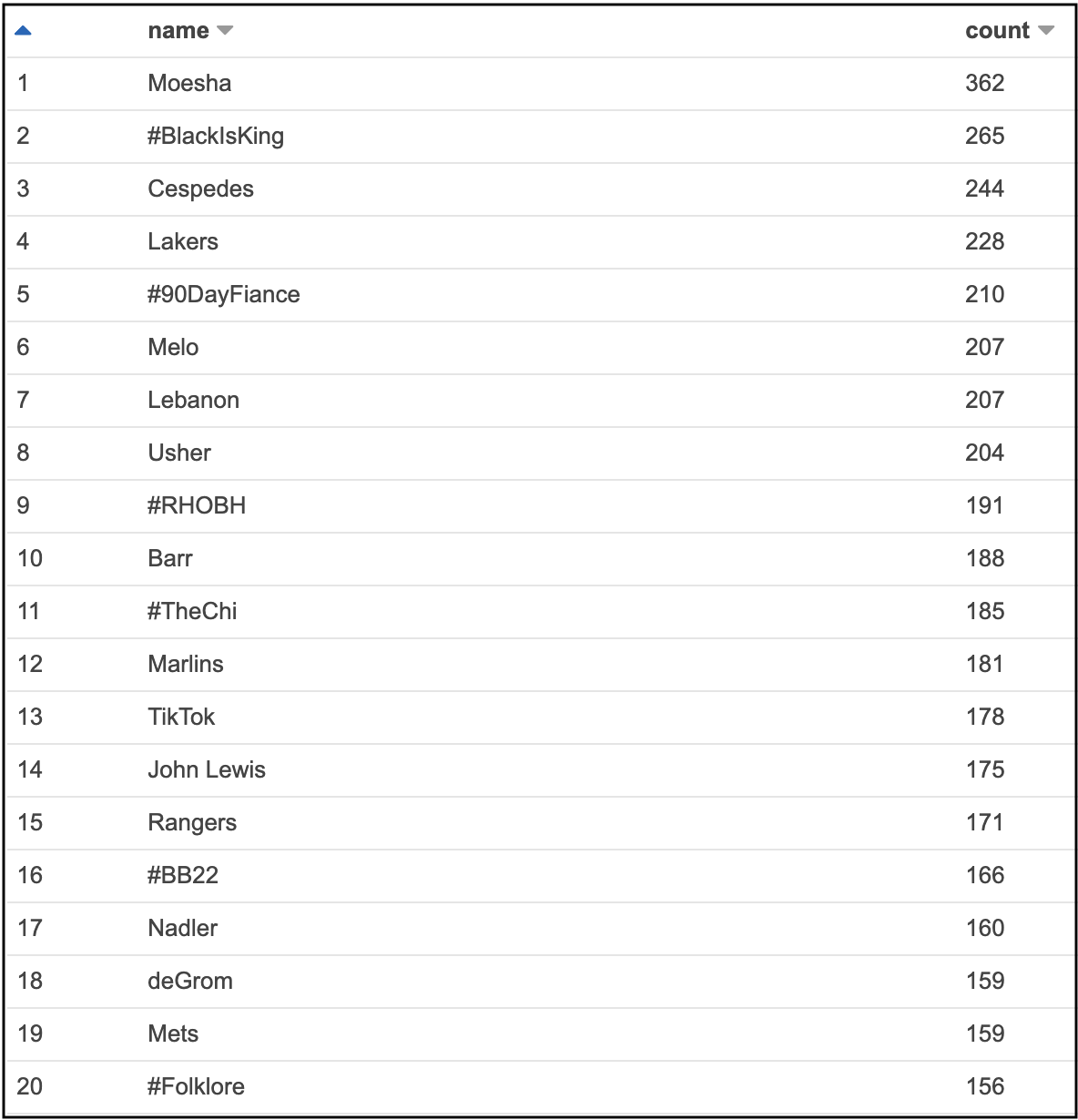
If you want more details about AWS Glue and Athena, I recommend reading this blog that gives more details on how to get started with these two services.
Conclusion
Creating a project that uses the Twitter API to analyze the results was relatively easy using the available AWS services. CDK really lets you focus on the architecture design instead of wasting time on trivial things like configurations and permissions.
Companies like Dataminr are built on Twitter and provide real-time information alerts which are really powerful, especially when they are received before major news organizations. Ippon Technologies USA also developed an internal tool that collects tweets -- Customer Oriented Sentiment Analysis (COSA), more details can be found on this blog.
Need help using the latest AWS technologies? Need help modernizing your legacy systems to implement these new tools? Ippon can help! Send us a line at contact@ippon.tech.
