

by Julien Margarido and Joffrey Derchu.
The Java world has great expectations for reactive programming. According to the manifesto, it enables programmers to build more resilient, elastic, responsive and message-driven applications. To put it simply, it is a better, faster and more modern paradigm to prevent application idling.
Spring 5 introduces a new model for reactive programming by incorporating the Spring reactive initiative, based on the Project Reactor. But does it do the job?
We have looked into the new functionalities offered by Spring, and we present our results from performance tests.
WARNING: Our results could be altered in a few weeks/months. Indeed, as of now, a real-world Spring sample has yet to be released, and the documentation is not complete. Spring 5 and Spring Boot 2 are still under development (Spring Framework 5.0.0 RC3, Spring Boot 2.0.0.M2), and Project Reactor is constantly evolving. Furthermore, there is still very little feedback from the community (JHipster, Spring, Reddit ...).
What’s new in Spring 5?
Spring framework has introduced a lot a new features.
One of the most important is the reactive programming.
Spring MVC and Spring WebFlux
Some of you may have tried to do reactive programming with the old Spring 4 technology, and if you did, you surely realized it was a real hassle. Spring 5 provides a new, easy-to-use module to do just that: spring-webflux. It does the same thing as its older brother spring-mvc, but in reactive mode. Let’s see how it works.
WebFlux mostly centers around two Project Reactor’s classes: Mono and Flux.
Mono is the reactive equivalent of CompletableFuture type, and allows the handling of a single object in a reactive way. Flux is its equivalent for multiple objects. They are handled just like Stream (get ready to use lambda expressions a lot). Thus, you may see code that looks like this:
reactiveService.getResults()
.mergeWith(Flux.interval(100))
.map(r -> r * 2)
.doOnNext(Service1::someObserver)
.doAfterTerminate(Service2::incrementTerminate);
They are both implementations of the Publisher interface of the Reactive Streams specification, and thus they need to subscribe to a Subscriber for the data to start flowing.
Luckily, the annotation-based programming model is still up-to-date, and the only difference with Spring MVC is that the methods of the REST layer now return a Mono or a Flux:
@PutMapping("/operations")
public Mono<Operation> updateOperation(@Valid @RequestBody Operation operation)
throws URISyntaxException {
log.debug("REST request to update Operation : {}", operation);
return operationRepository.save(operation);
}
Spring knows what to do with the Monos or Fluxs. No need to fret; it will pass the encapsulated objects to the front-end once it has received them.
Concerning the communication with the databases, Spring 5 supports the reactive drivers for Cassandra, CouchBase, MongoDB, and Redis, which work with Spring Data.
Here is an example of a MongoDB repository:
@Repository
public interface BankAccountRepository extends ReactiveMongoRepository<BankAccount,String> {
Mono<BankAccount> getFirstByBalanceEndingWith(BigDecimal bigDecimal);
Mono<Long> countByBalanceEquals(BigDecimal bigDecimal);
Flux<BankAccount> findAllByIdBefore(UUID uuid);
}
Our tests
Why?
Reactive programming is going on a tear right now, and of course, Pivotal has logically decided to integrate it in its framework, with the promise of better performance and scalability. Sadly, without giving any studies or figures on it...
How?
By making stress tests (with Gatling) on different JHipster generated applications (MySQL, Mongo, entities, …), in production mode.
Each of these applications has been duplicated and modified multiple times, to ensure that we have a large array of values for our tests.
For example, for a MySQL application, we have created four similar applications:
- with Spring 4 (as you can actually generate with JHipster)
- with Spring 5 (only the migration)
- with Spring 5 and reactive programming (on the REST layer)
- with Spring 5 and reactive programming (only on one entity’s RestController class)
For Mongo, which has an asynchronous driver, we have created applications:
- with Spring 4 (as you can actually generate with JHipster)
- with Spring 5 (only the migration)
- with Spring 5 and reactive programming (on the REST layer)
- with Spring 5 and reactive programming (only on one entity’s RestController class)
- with Spring 5 and reactive programming on the entity all the way down to the repository.
Spring allows the programmer to configure his own scheduler (the thread-pool which handles reactive calls). Thus, when using reactive programming, only on the REST layer (not on the entities), we tried different schedulers: Schedulers.parallel() uses one thread per CPU core, while Schedulers.elastic() creates threads dynamically.
Each test consists of launching, with Gatling, 5000/10000/15000 users simultaneously, each performing the actions described in a scenario:
scenario("Test the Operation entity")
.exec(http("First unauthenticated request")
.get("/api/account")
.headers(headers_http)
.check(status.is(401))).exitHereIfFailed
.pause(5)
.exec(http("Authentication")
.post("/api/authenticate")
.headers(headers_http_authentication)
.body(StringBody("""{"username":"admin", "password":"admin"}""")).asJSON
.check(header.get("Authorization").saveAs("access_token"))).exitHereIfFailed
.pause(1)
.repeat(2) {
exec(http("Authenticated request")
.get("/api/account")
.headers(headers_http_authenticated)
.check(status.is(200)))
.pause(5)
}
.repeat(2) {
exec(http("Get all operations")
.get("/api/operations")
.headers(headers_http_authenticated)
.check(status.is(200)))
.pause(5 seconds, 10 seconds)
.exec(http("Create new operation")
.post("/api/operations")
.headers(headers_http_authenticated)
.body(StringBody("""{"id":null, "date":"2020-01-01T00:00:00.000Z", "description":"SAMPLE_TEXT", "amount":"1"}""")).asJSON
.check(status.is(201))
.check(headerRegex("Location", "(.*)").saveAs("new_operation_url"))).exitHereIfFailed
.pause(5)
.repeat(8) {
exec(http("Get created operation")
.get("${new_operation_url}")
.headers(headers_http_authenticated))
.pause(3)
}
.exec(http("Delete created operation")
.delete("${new_operation_url}")
.headers(headers_http_authenticated))
.pause(5)
}
Then, we are able to analyze these results by comparing times or errors/crash.
Our big configuration:
- Machine 1 used as a Spring Boot server and a local database: i7-4790K 4GHz - 16Go - SSD - Ubuntu 16.04 64bits
- Machine 2 used as a Gatling client: i7-4790K 4GHz - 16Go - SSD - Ubuntu 16.04 64bits
- Cisco SG100-24 24-Port Gigabit Switch

Results
The following results have been generated from simulations with 5000 users. We also made tests with 10000/15000/20000 users, but the results were not coherent due to the high number of errors.
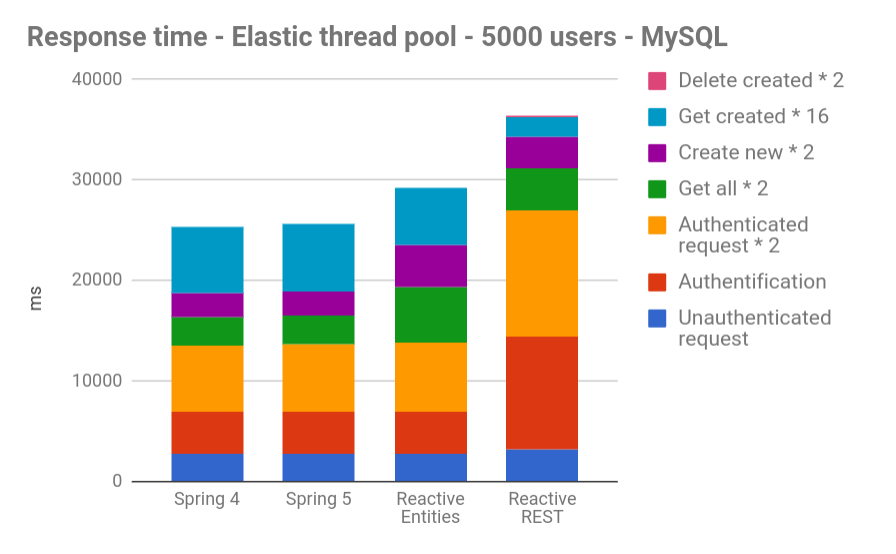
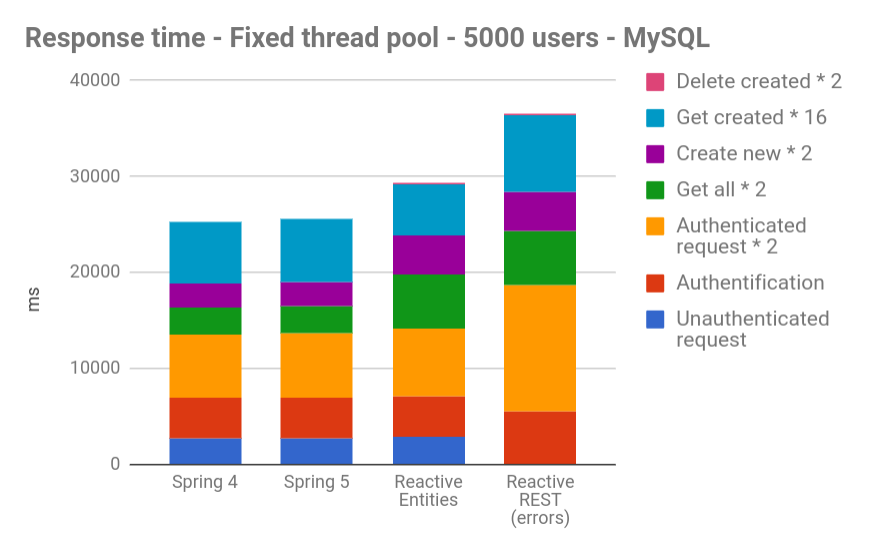
With a MySQL-based JHipster application:
(Note: The results below do not include the pauses in the scenario.)
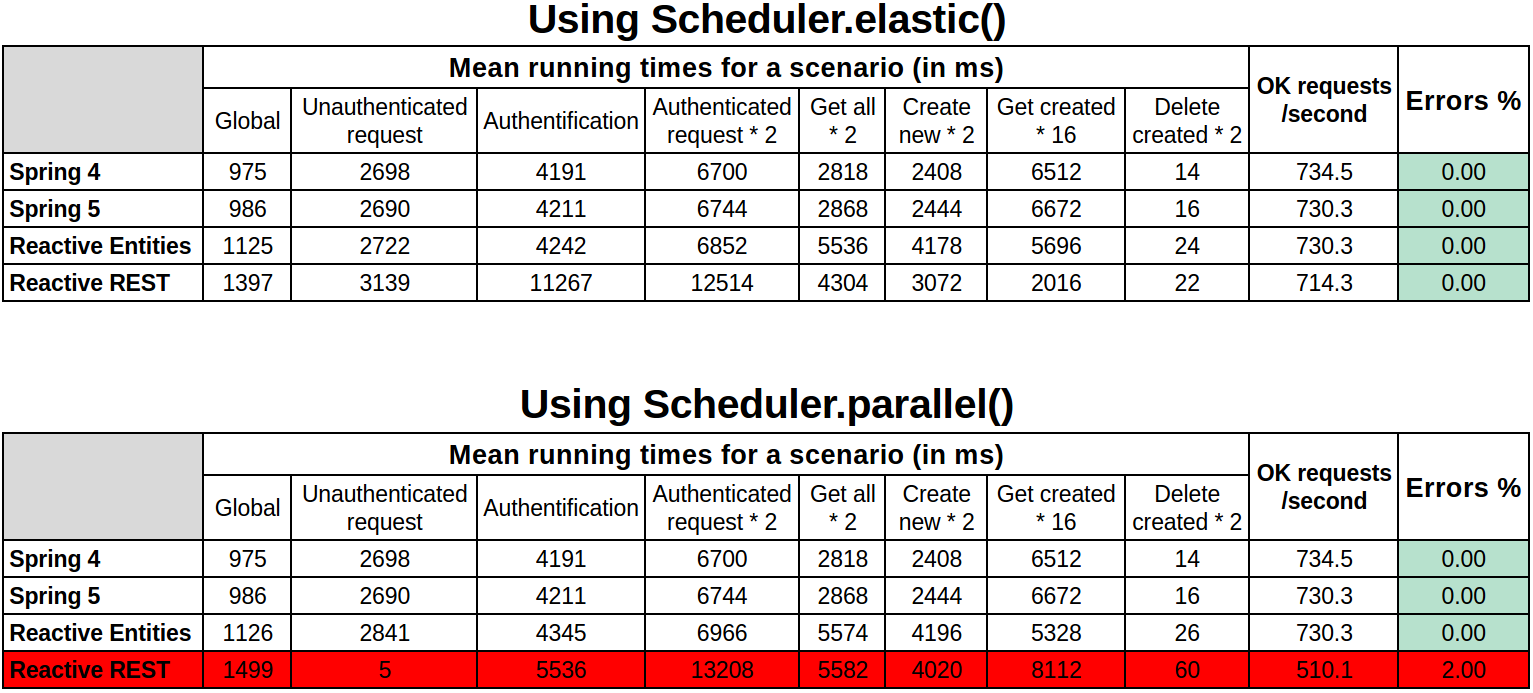
Erroneous data (errors > 0%).
When a user gets an error during his Gatling scenario, his simulation is stopped. So, if there are some errors, there are fewer users requesting the server, and thus a lower load and altered times.
The errors can be of several kinds: timeouts, threshold of DB connections reached, concurrency problems of bean creation/destruction with Spring, ...
These graphs show the total time a user takes to run our Gatling scenario.
With a Mongo-based JHipster application:
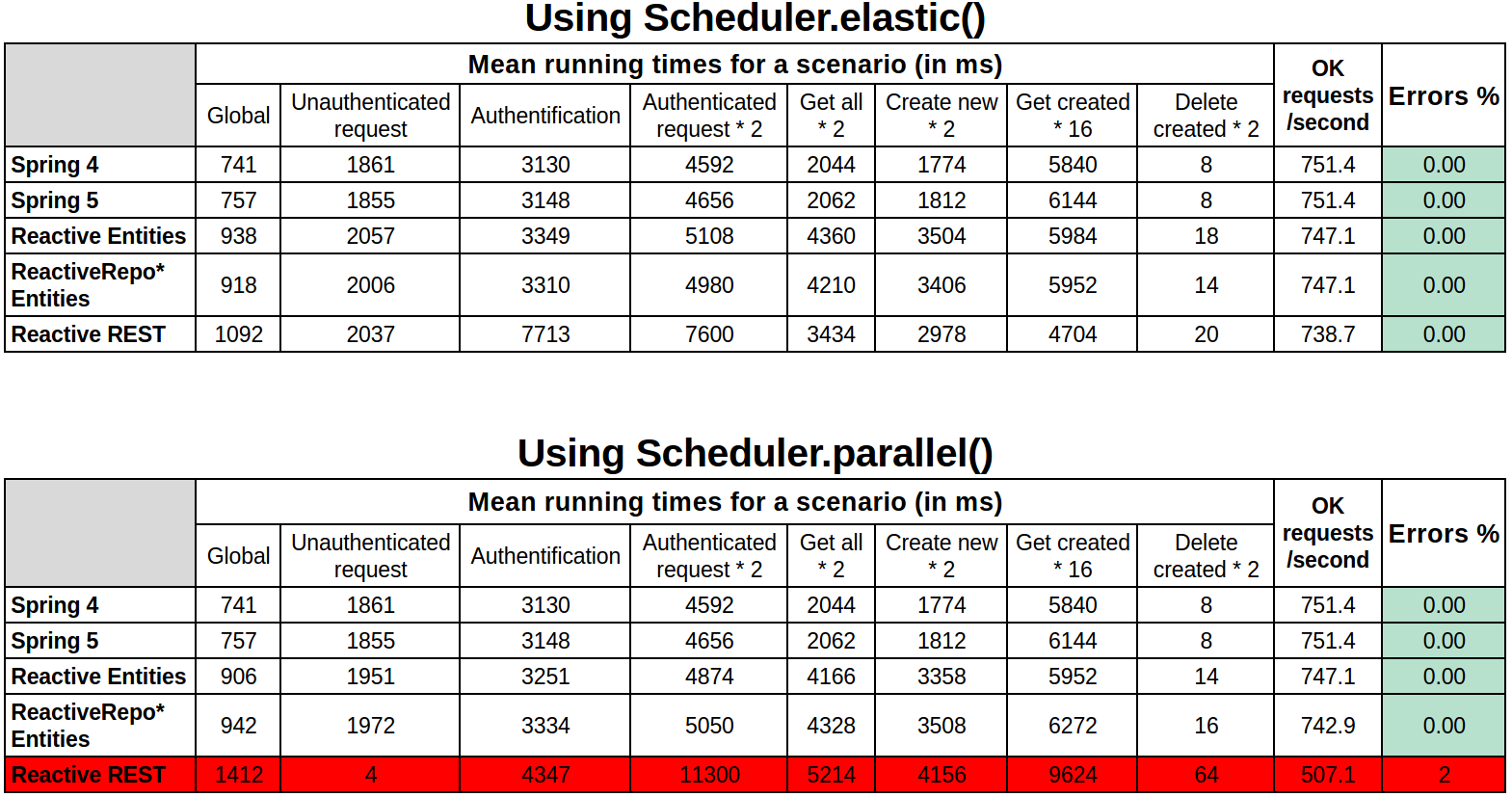
*ReactiveRepo: see ReactiveMongoRepository.java
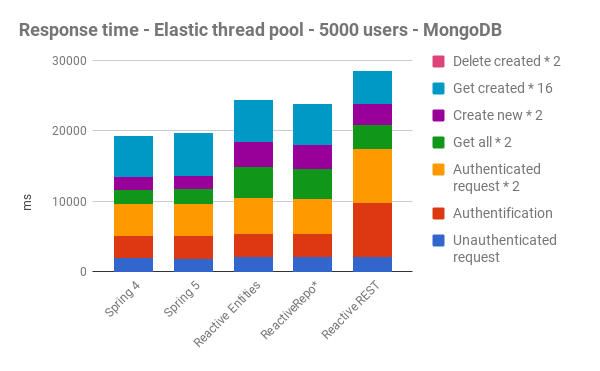
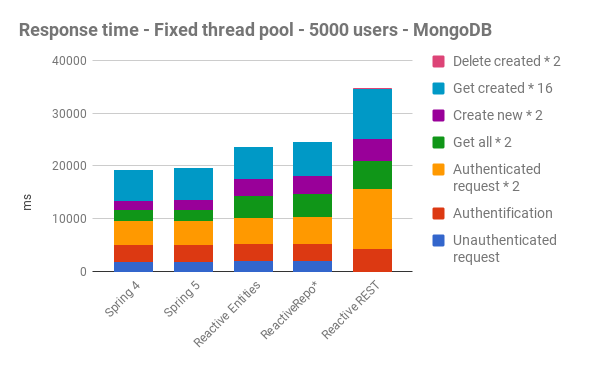
Regarding the execution times
As we can see, overall, Reactive apps are slower than “classic” Spring apps.
For MySQL, it was predictable because of all the locks the database sets up during its use, and as there is no official reactive/async driver.
For Mongo, there is a complete stack of reactive components (driver, repository, …), but even with that, performance is worse.
Besides, we have noticed no visible improvement in speed between Spring 4 and Spring 5, even when no reactive programing was added.
Regarding scalability
Regarding scalability, Reactive apps can handle fewer users than Spring4/Spring5 apps.
Indeed, we noticed that difference by simulating 5000, 10000, 15000 and 20000 users with Gatling.
Starting from 10000 users, we have too many errors on Reactive apps, with often more than 40% of KO requests.
Conclusion
- No improvement in speed was observed with our reactive apps (the Gatling results are even slightly worse).
- Concerning user-friendliness, reactive programming does not add a lot of new code, but it certainly is a more complex way of coding (and debugging…). A quick Java 8 refresher might be required.
- The main problem right now is the lack of documentation. It has been our greatest obstacle in generating test apps, and we may have missed a crucial point because of that.
We therefore advise not to jump too quickly on reactive programming and wait for more feedback. Spring WebFlux has not yet proved its superiority over Spring MVC.
You can find our code in this repository: jhipster/webflux-jhipster.
The Gatling results can be found in the gatling-results directory at the root of each module.
