

Build & Deploy
The release management process is the process of getting the new version of your code out into your environments and eventually into production. There are numerous steps to this deployment process, and luckily much of this process lends itself easily to automation. The core product that you are going to scale is your artifact, your code. Focusing on the artifact can be a paradigm shift from usual deployment planning. This article seeks to explore some of the possible philosophies and choices about your artifact, and when to use them.
One of the first steps in a standard deployment, or release management process, is the build process. The expected result of the build process is some kind of artifact. This artifact represents “this” version of your product (a release), but does not always contain the necessary configurations to make it function in a selected environment. Your deploy artifact is the product that will be replicated across resources when scaling or deploying to another environment.
Regardless of the level of adoption of DevOps principles in your organization, there is a thin line drawn between Build and Deploy. Moving from build toward deploy, this line indicates when you have produced an “Artifact”, a pivot point in the process. This is the artifact that you will deploy to each environment in succession as it passes each testing phase. Once in production this is also the artifact that will be used to scale out your service. When moving to a DevOps model the type of Artifact that you want your deployment to operate from is an important consideration.
The Build Artifact Model
Being kind of the “classic” approach, the ins and outs of the Build Artifact Model are well understood, and the process usually looks like:
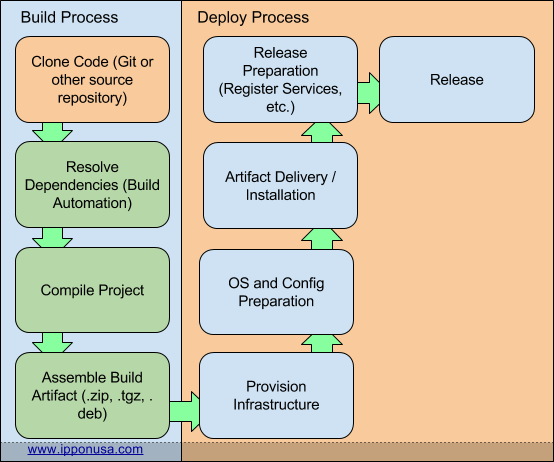
The benefits that the Build Artifact Model presents are that it is highly tangible and well understood by your configuration management system. This is a good choice for systems that will need maintenance or continuous interaction with a configuration management system, usually legacy solutions.
The detractor to the Build Artifact Model is that it does not lend itself to Automated Scaling Processes very easily. The process of repeating the ENTIRE deploy process for every entity that is added to your cluster is slow and cumbersome.
The Infrastructure Artifact Model (e.g. Docker)
Infrastructure artifacts differentiate themselves in that the deploy process starts later than in the Build Artifact Model, effectively moving your Artifact “up the stack”. The Infrastructure Artifact Model looks somewhat like this:
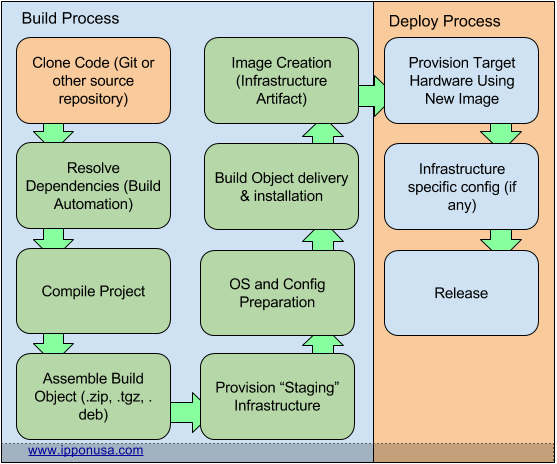
The benefits to the Infrastructure Artifact Model are that scaling is a breeze, your image already contains everything that it needs to make it go, just a bit of touch-up. Also, you can now not only take a particular version of the code with you from environment to environment (as it works its way to production), but you can take the infrastructure too.
The downside however is that since this is your artifact, if it requires manual actions to be configured for particular environments or situations, it will have to be managed by your configuration management system after the deployment to bring it up to speed on its situation. This can even be expounded upon, by using metadata from service registries, and key management systems. Your applications should be designed to self-configure, alleviating this potential concern, and providing an additional layer of automation.
There is a helpful piece of software built around the concept of an Infrastructure Artifact. With Packer (or BoxFuse) you can describe what kind of “output” you want by specifying “builders”. These builders produce “Images” (essentially Infrastructure Artifacts) that can then be put into service, as a container, or Amazon AMI.
Which model should I use?
It’s becoming more and more common that an application designed for the cloud be designed in accordance with the Infrastructure Artifact Model. As time goes on I see it as the natural progression that more and more deployments will rely on this route. However that does not alleviate us from the needs of migrating and supporting our legacy applications in the cloud anytime soon. In dealing with those legacy applications, using the standard Build Artifact Model is going to be the path of least resistance.
The Artifact represents the point at which your deployment process will be repeated for each entity serving it. Between the two choices it’s easy to see which is less involved, and therefore less prone to error:
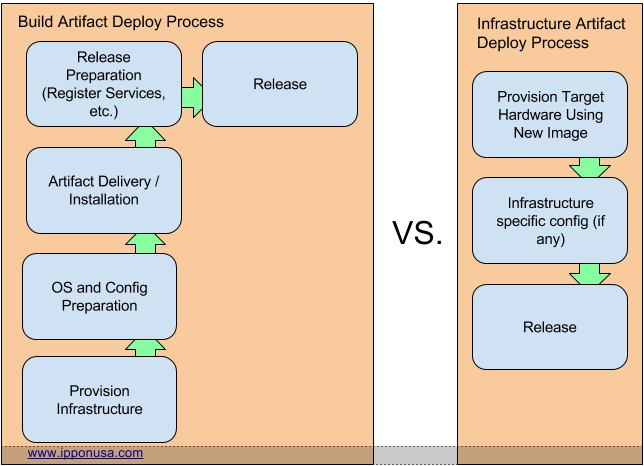
If legacy services do need to be autoscaled, or quickly provisioned, you can manage a hybrid situation, where you create a deployed image per environment (or per applicable situation), and manage those images. This will satisfy the requirements to provide an AMI for AWS Launch Configurations, but the downside becomes that you now have to manage many more artifacts than with the other models.
Conclusions
I see the reliance on the first option, Build Artifacts, as something that will work well for applications that need heavy or complicated configuration. Legacy apps that have not been designed with the cloud in mind will have a greater reliance on their environment being specifically crafted for them. On the other hand, newer solutions may have greater occasion to be designed with service registries, and key servers / services in mind to assist in providing that configuration in a more real-time fashion, and allowing the faster deployment provided by an Infrastructure Artifact.
