

Databricks is doing a lot of optimization and caching by default to have jobs and queries run fast enough. Poorly designed tables (like having too many small partitions) or using a small cluster will obviously impact your performance. To avoid that, I recommend paying attention to those details when creating tables or clusters. In this blog, I will explain multiple techniques that enhance what Databricks is doing under the hood.
A fixed-size cluster is usually better than autoscaling
Having a cluster that autoscales is great if you want to save money and if you don't have strict SLAs on your job/query runtime. But you will realize that it is usually better to use a cluster with a fixed-size, especially if you know the volume of data being processed in advance. Upsizing your cluster is not instant and will usually take 3-4 minutes to have new worker nodes ready because of their initialization script.
Due to that delay, you will notice that your cluster is constantly growing and shrinking like a "roller coaster":
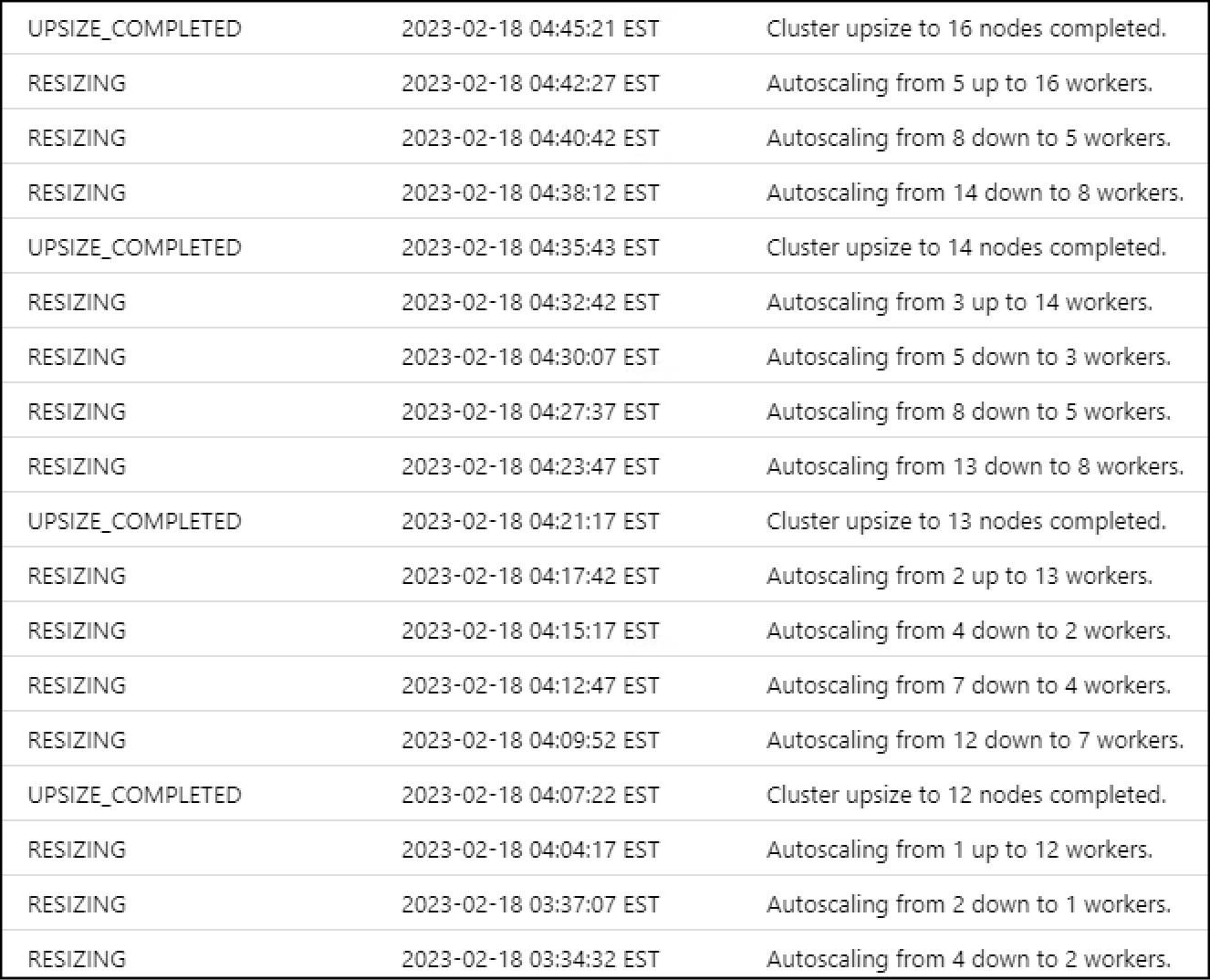
Don't get me wrong, this is the whole point of autoscaling but the wait time between each upsizing events has an impact. A streaming job will have more data to process by the time the first upsize is finished and then will probably have to upsize again as new data is processed. If your cluster has been idle with a low number of workers - running a heavy command will take longer because it will have to first complete the upsize before starting that command.
One last detail is due to node termination, any data cached will be lost when the cluster completes its downsizing. If cost savings is of a higher priority than performance - autoscaling is definitely the way to go! Be sure to read Databricks' best practices about autoscaling.
Small cluster with larger VMs is better for complex ETL
A complex ETL job that requires unions and joins across multiple tables will run faster on a cluster that uses very large instance types. Having a reduced number of workers will minimize the amount of data shuffled. Your large workers will also have more RAM available and have less OUT_OF_MEMORY errors like below (DLT pipeline):

A low number of large instance types is always better than a high number of small instance types. For more details, I recommend reading the Databricks page about cluster sizing considerations.
One risk to consider is spot termination of a large worker will have way more of an impact on your cluster's resources than losing a small worker.
Optimize and Z-ordering are your friends
The Optimize command is very useful and will consolidate small files into larger ones to improve your query speed. You can even select a subset of your data by inputing a where in the optimize command. Databricks recommends running optimize every night when the EC2 spot prices are low.
Z-ordering can be run on columns that are often used in your query's predicates and are high cardinality. For example, if you have a table with daily stock prices, you will want to z-order on the stock ticker column because there is a high number of tickers. Ticker will often be in your queries as it is a common predicate. Partitioning on the ticker column is not recommended and will create too many small partitions. I recommend reading this Databricks page about z-ordering for more information.
Cache your data!
This advice will sound basic but caching your data using disk caching is still the standard method to make your queries faster. Databricks automatically caches your data based on your queries but you can also preload data beforehand by using the CACHE SELECT command. It is very specific to a query and might not fit your use case if the query you want to cache is built dynamically. But for a specific query that is run often, pre-caching it will have a big impact.
Also, caching should be disabled when comparing query speed to avoid having inaccurate results. For more details about caching, please read this Databricks page.
Let Databricks partition your data
Partitioning your data is very important and you should always think before picking which columns to partition by. For tables with less than 1TB of data, Databricks actually recommends defining no partition columns and to let Delta Lake handle it for you with its built-in features and optimizations. Tables can still be partitioned on specific columns but avoid using one with high cardinality because several small partitions will impact query speed. For more details about partitioning and Databricks recommendations, here is the official Databricks page.
Generate columns for your custom partitions
If you decide to partition your table on specific columns, you might to take a look at Delta Lake generated columns. This will be very useful if your data is partitionned on a date/timestamp column because you will be able to query on year/month/day and use a partition filter. With the previous stock price table example, the column file_date (date of the stock price) can be used to generate a file_year and file_month column and then partition our table with those 2 columns. Then we can easily retrieve all prices for a given year or month and have Delta Lake generate the correct partition filter:
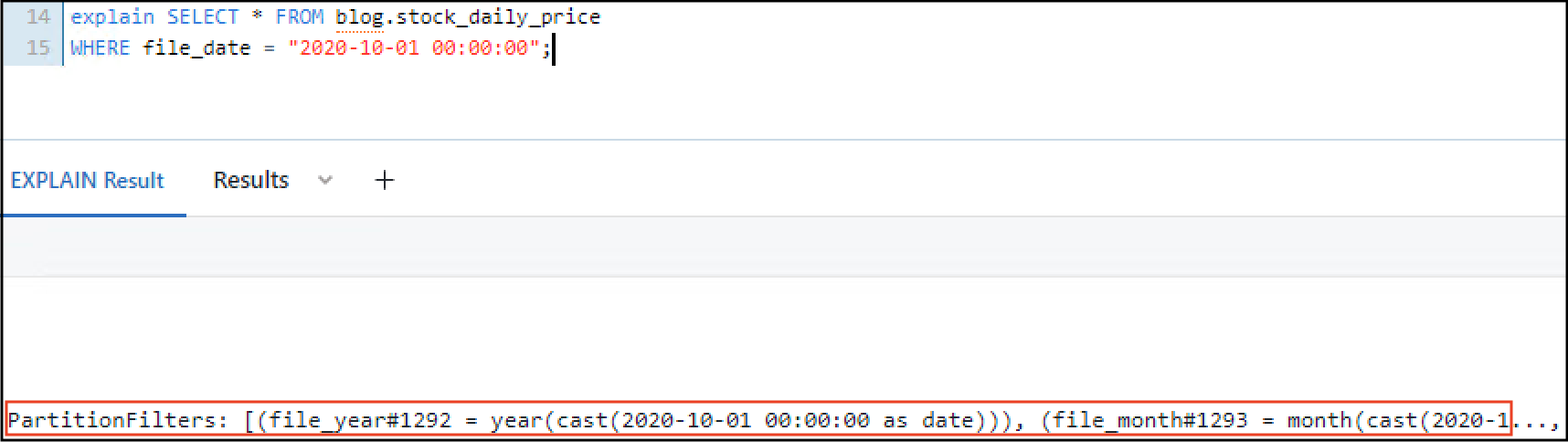
You can see that 2020 was correctly used as a partition filter and that value was generated from file_date.
Conclusion
Multiple approaches can improve query speed or job duration but having a poorly designed table will be very hard to optimize. Most of the time, nothing needs to be done and the default behavior from Databricks will be enough. But depending on your end user queries, z-ordering and caching will help your queries perform faster.
Need help with your existing Databricks Lakehouse Platform? Or do you need help using the latest Data lake technology? Ippon can help! Send us a line at contact@ippon.tech.
