

For those who do not already know the Keycloak product, it is the main IAM (Identity and Access Management) free open source product initiative created in 2014, which is part of the JBoss community project and under the stewardship of Red Hat since 2018.
This product strives to conform to Standard Protocols such as OpenID Connect, OAuth 2.0 and SAML 2.0 and natively handles the main user/identity management uses cases:
- User Registration,
- User Federation (LDAP, Active Directory),
- Single Sign-On,
- Social login,
- Identity brokering,
- 2-factor authentication,
- etc.
They have made some improvements to increase performance and reliability, it works well with broadcasting thanks to the UDP protocol, however when it comes to deal with Cloud architectures that do not natively support this protocol, it begins to be an 'assault course' as internet is poor on this subject.
It is then that the tedious work begins -- making Wildfly cluster works with TCP.
You will see in this article that we have not obtained the best expected results, but we have somehow found an acceptable state.
It is made up of 4 parts:
- The overall AWS architecture and infrastructure + How to anticipate EC2 behaviour using Docker.
- Wildfly/JGroup server configuration.
- How to scale Gatling clients based on ECS + The approach to build the load tests.
- Load test chart results, interpretations and suggestions.
This feedback presents a solution that deploys Keycloak directly on EC2 with AWS standard resources, but it won’t differ a lot from a containerized solution (Kubernetes or not) when dealing with the Keycloak configuration itself.
Our main constraints
Here is the list:
- Avoid containers in Production (not even into our AMIs).
This forced us to set up a bundle to be ready to be executed directly on EC2 instances (nonetheless, it gives more control over the VM). - Cluster nodes should communicate in a Cloud environment (i.e. over TCP protocol).
- Architecture should handle at least 1000 logins per hour.
This number would probably increase with the rollout of other new projects. - No necessity to be cross region but at least on 2 availability zones.
Of course, it must support failover. - Use the standalone clustered mode -- no need to use a domain clustered architecture (it eases deployment and configuration).
Infinispan (the JGroup caching layer) will be embedded into the Keycloak nodes.
This choice can be debatable, but the configuration is not supposed to change very often, and the availability window is during the daily European work hours, so it leaves the whole night to handle new deployments. - Host data into Aurora SQL database (highly available and automatically replicated by AWS).
There is no user federation into a dedicated subsystem like LDAP or AD, thus users will be stored with all other Keycloak data into the database.
A basic EC2 architecture based on the JGroup TCP protocol
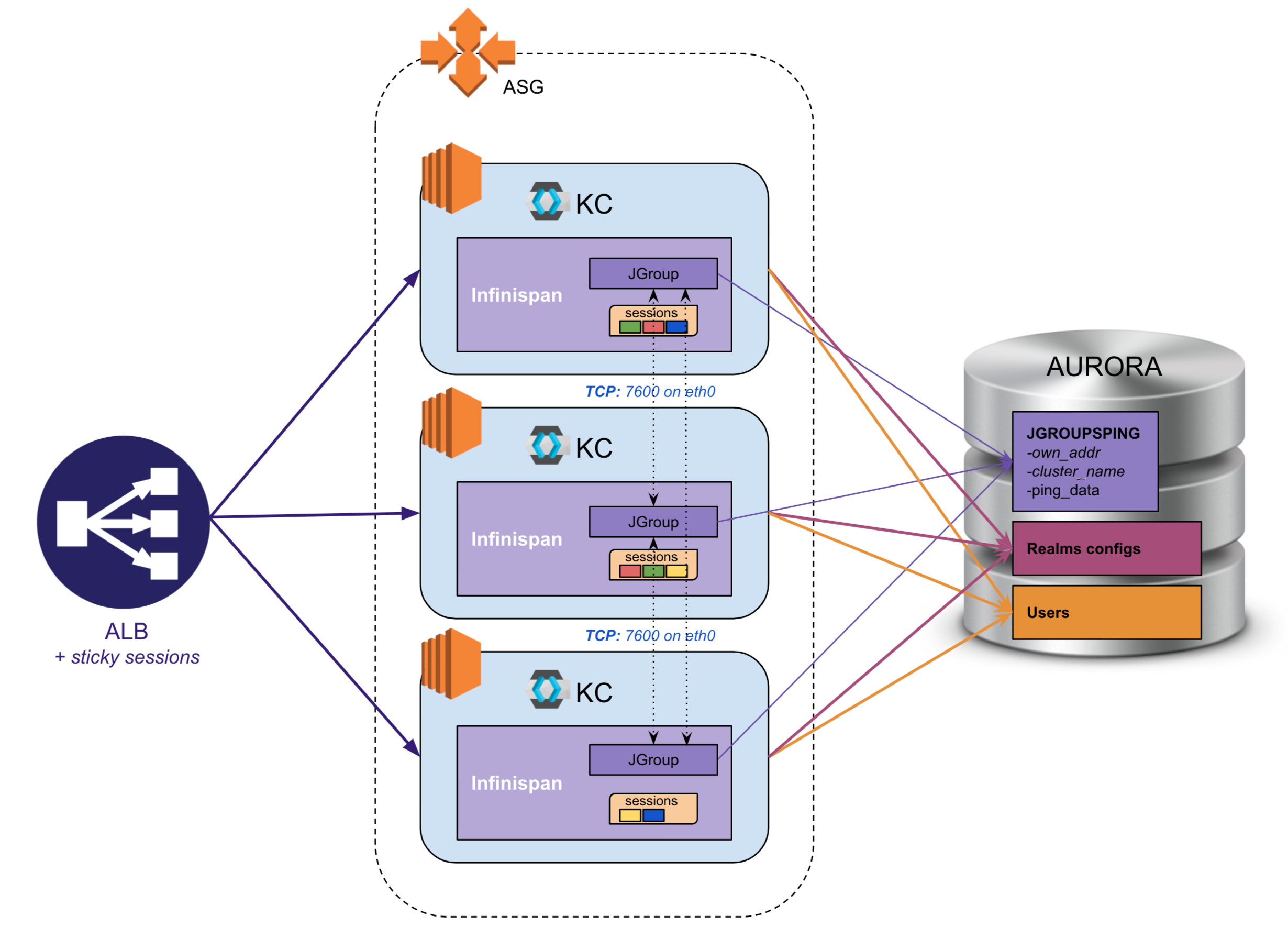
All requests will be routed through the AWS ALB (Application Load Balancer).
It is up to you to make the HTTPS protocol rupture on the ALB, but it supposes that all that is behind is well isolated in a private Network thanks to NACL and Security Groups (only a bastion can have access). The advantage is to let AWS handle the certificate maintenance at the ELB level and to ease the Keycloak configuration.
In order to improve performance, it is important to call as much as possible the nodes that already have the information (session cache etc.). Thus, we activate the session affinity on the ALB.
The cookies are useful only to browser clients. If like us, you have an API Management CORS layer, there would not be any affinity on the api call requests (these requests are by far more numerous than browser ones).
Maybe you should consider:
- Self-supporting tokens (ciphered tokens that have all data -- no need to validate the token against the authorization server). Be careful in this case you would not be able to invalidate tokens from Keycloak, thus, you should use very short TTL.
- Token cache to remain stateless (the TTL should also be very short, few minutes and of course lower than the token TTL).
The performance/cost gains all come with slight security disadvantages.
The first criteria to take into consideration with Keycloak is the CPU. Indeed, you will see it on the charts, the login phase is the one which has the greatest impact.
It will require a lot of CPUs to resolve the default 27500 hashing iterations with pbkdf2-sha256 algorithm (cf. 'password security' policies of the Keycloak console).
On this project, we opted for a T3A.small instance, as 2GB of RAM was more than enough.
The 'T3A' type is a burstable one: that means that it can increase the CPU on a short period if needed.
In order to avoid strong additional costs, you will control that it won’t be above the vCPU baseline performance most of the time. Help yourself with CloudWatch metrics and keep in mind that it shows only one vCPU metric ('T3A' is 2 * 20% of vCPU).
The ASG (Auto-Scaling Group) should be tuned according to the dynamic of the CPU consumption of your EC2s along the time.
If it is common to have huge peaks, you can provision in advance some additional EC2 instances, if you can anticipate it. It is safer and less complex, but it adds of course additional costs.
Otherwise, you can decrease a little the threshold of the scale-out detection, or even use the AWS step scaling strategies that can scale many instances at a time.
I would not advise you to have aggressive downscale and it will depend on the number of shards you have (for instance 3 scale-in at a time, means at least a shard of 4).
The alarms thresholds will be adjusted thanks to the ASG metrics, such as “CPUSurplusCreditsCharged” (the objective is to be close to 0).
 This kind of metrics needs at least 24h of observations.
This kind of metrics needs at least 24h of observations.
Idled instances can consume some CPU, so adjust the lowest thresholds in consequence.
Another important aspect is the health check strategy. Keycloak does not natively provide a default endpoint, thus the best for now is to test, with the ALB, an HTTP code 200 on the master realm: /auth/realms/master.
In order to preserve our cluster, it is mandatory to identify the right 'HealthCheckType' of the ASG:
-
EC2 (Default): --the one we picked-- Check on the instance.
The advantage of this mode is that if the server is under very huge load, the health check will fail but the instance won’t be removed.
The downside is that if the Keycloak that runs into the EC2, crashes or experiences an out of memory error, the instance will not be removed and that will add additional costs. To lower the risk, we use Keycloak as a service (systemd), it will usually be restarted whenever it gets terminated.
-
ELB: Check on the load balancer.
The advantage is to be sure to have functional instances alive, but if the cluster receives a huge load, all the instances will not answer to health checks. They will be removed one by one and it will increase exponentially until the cluster crashes.
Then, it won’t recover without manual assistance. As the ELB use a round robin strategy (1 overloaded instance ~ all instances overloaded), it could be useful, if we find a way to limit the load inside the instance, to ensure that the health check endpoint always respond and reject the other request's endpoint ones with
502HTTP code if the maximum acceptable is reached (be aware that we cannot base our limit on the number of requests, as some, like logins, consumes more).
That’s it for the architecture and the most important information about the AWS platform.
No Docker in Production? How to use it cleverly for development?
Keycloak is available here. If you have a JDK, you will be able to run it and access the console on the 8080 default port without any further configuration.
You will then need to spend a lot of time reading the tedious documentation and integrate it well into your ecosystem.
Fortunately, like most providers, they also bring an out-of-the-box Docker container image. You can find the link on the Keycloak documentation (you could still download it too on DockerHub).
To avoid 'reinventing the wheel', we have built our stack from an official image (it was first a 4.8 that we then have migrated to the 8.0 since the writing of this article).
We could have remained on this basis and then write a script executed by the CI/CD chain to package it against the EC2 instance requirements, but it would have been too complex and boresome to ensure that what works on our local development environment will run as well on the EC2.
Thus, we have decided to start with an extraction of all the content from a running image into our local disk on /tmp/keycloak-export directory:
docker-compose up -d
docker cp keycloak_1:/opt/keycloak /tmp/keycloak-export/
From there, we have constructed our own image based on an Amazon Linux one, to run it locally. Our targeted docker file’s first lines looks like:
FROM amazonlinux:latest
ENV JAVA_HOME=/usr/lib/jvm/java
ENV JDK_VERSION=1.8.0
RUN yum -y install unzip hostname shadow-utils java-${JDK_VERSION}-openjdk-devel.x86_64 jq \
&& yum clean all
...
The Amazon Linux AMI is continuously updated to the latest. We opt for a Linux one as it is the one that has the cheapest EC2 instance costs.
If you wish to test a Keycloak cluster on local environment, you can scale with the following command (‘keycloak’ is the docker-compose service name):
docker-compose up --scale keycloak=2 -d keycloak
In order to push further the simplifications for the CI/CD chain, we have written a script that packages/creates a bundle of the Keycloak deliverable. It simulates the packaging phase on local and the same script is reused by the Gitlab CI build stage.
Another dedicated docker file will simulate the few lines the AMI packager script will execute for installing this bundle:
FROM amazonlinux:latest
RUN yum -y install tar gzip && \
yum clean all
COPY ./bundle /
RUN chmod +x /bundle-keycloak.tar.gz
RUN tar zxvf /bundle-keycloak.tar.gz \
&& chmod -R +x /opt/keycloak/scripts
# Put in this file all the yum install libs that you will need
RUN /opt/keycloak/scripts/setup/install-deps.sh
COPY ./scripts/docker/entrypoint.sh /opt/keycloak/scripts/docker/entrypoint.sh
# Manage users group
USER root
RUN useradd jboss \
&& usermod -a -G jboss jboss \
&& chown -R jboss:jboss /opt/keycloak
RUN cd /opt/keycloak
ENTRYPOINT ["/opt/keycloak/scripts/docker/entrypoint.sh"]
You can see that the Dockerfile is very simple, it unzips the bundle, executes some mandatory libs installations (that will also be called by the IaC scripts and should not contain additional code) and sets the entrypoint, nothing more. This Dockerfile will then be launched to validate that Keycloak is working correctly in the simulated EC2 context.
Thus, once the setup was coherent between the keycloak development project and the IAAS scripts, we have never experienced problems from code that is valid on local but not on AWS.
Obviously, the resources such as Aurora, ELB etc. could not be simulated, but with the help of a mysql, load-balancer (we used traefik) and mailhog (for smtp emulation) services in our compose file, we were able to remain close to the reality and make us anticipate most cases…
In the next part, you will find a way to configure the Keycloak servers and make the nodes communicate together in a cluster.
